



最近某站很火的AI孙燕姿,本着本公众号高可用的宗旨,自己没有复现的情况下一直没有发文,终于周末抽空复现一次,效果非常好。
高度复刻声音是存在法律风险的,即便不用于翻唱歌曲,这套工具做为一套声音美化的工具,还可以。。。
某站有视频教程,也有整合包下载,但是整合包和视频内容有出入,但坑还是不少,现整理笔记,并且推荐一些工具,让大家少踩坑。
先听两段音频:
<起风了>原声:
主要步骤:
-
音频收集 -
人声提取 UVR5 -
人声切割为3-15秒的片段 -
模型训练 -
目标音频推理
一、 音频收集
需要训练一个人声模型,需要30分钟到2小时的清晰音频。如果目标是某位歌手,则可以从网上下载MP3。
由于歌曲有近半时间是纯音乐,所以推荐至少20首MP3,时长要超过1小时。
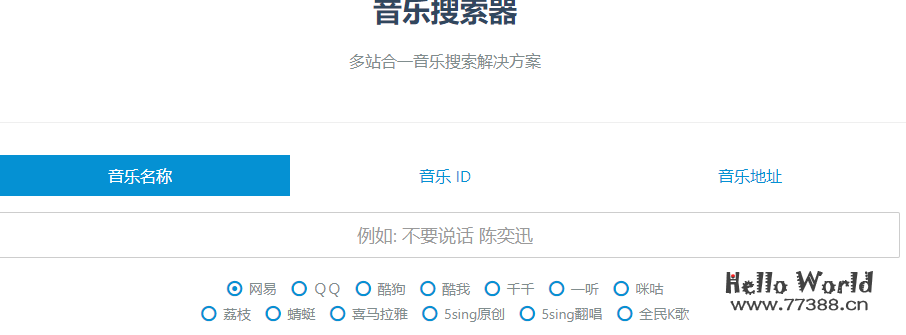
MP3下载网站,推荐 y.in2s.net ,无需安装客户端,无需注册即可下载音乐,音源丰富:
如果需要训练自己声音,则需要找一个安静的空间进行录音。当然也可以后期降噪处理。
推荐开源音频处理软件(带降噪功能):audacityteam.org
二、人声提取
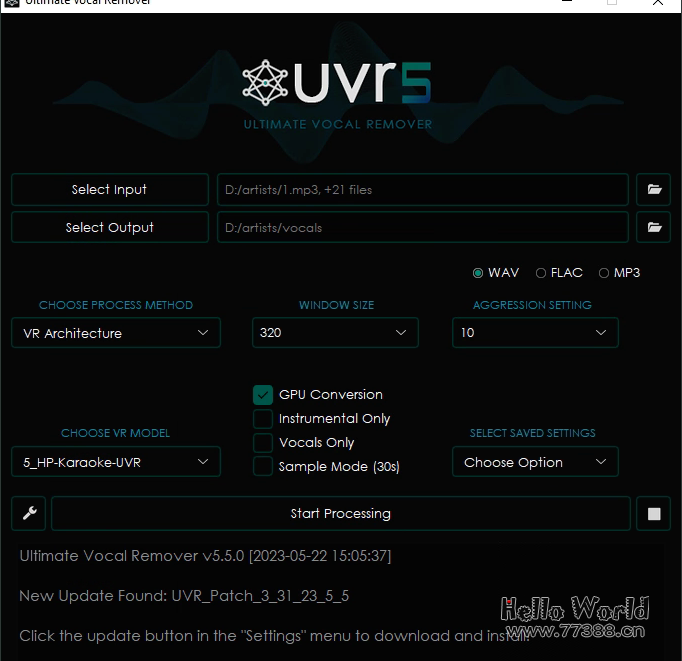
使用开源软件 ultimatevocalremover.com, 能将歌曲中的人声提取出来。
将刚才下载的MP3放到一个目录中,以纯数字和字母命名。
输出目录请另行设置,可设置为mp3目录内的子目录 vocals,输出格式为.wav格式:
22首歌提取人声,共花掉15分钟时间:

输出目录中包含了带音乐的原文件,这些文件文件名添加了 (Instrumental),把这些文件通通删掉。
留一带(Vocals)的文件,将之命名为纯数字,如: 1.wav, 2.wav
三、音频切割
系统无法处理过长的音频,这时就需要将长频频切割为单个3-15秒的音频。
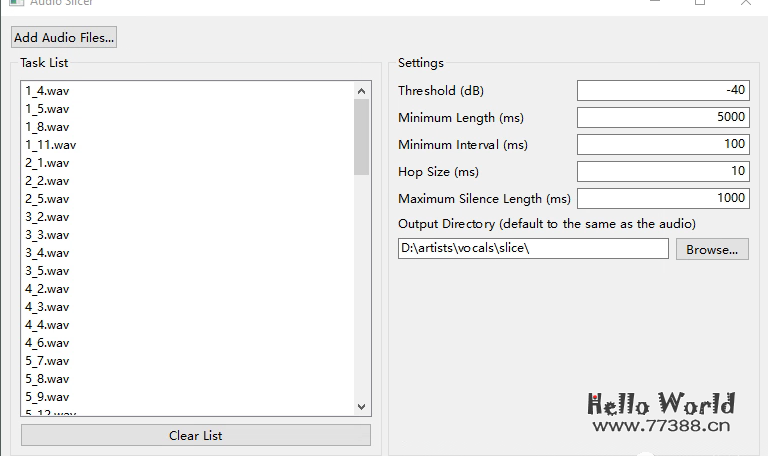
这里使用 slicer-gui 这个软件,参数如下图:
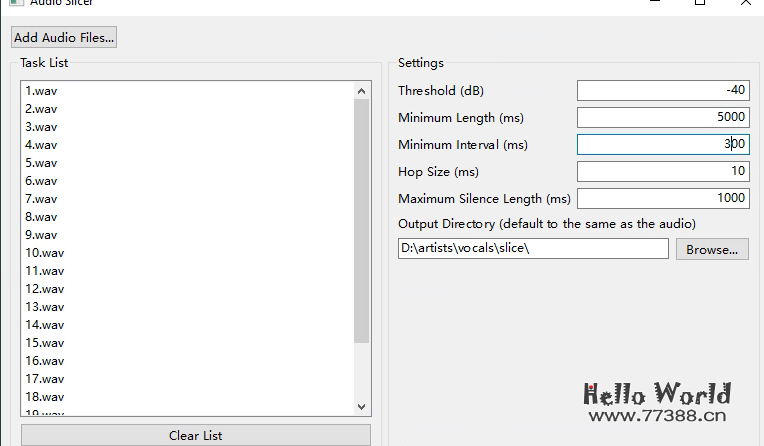
22首歌曲不到一分钟就切割完成,非常快。
打开输出目录,按音频时长排序,将4秒以内及15秒以上的音频删除。
3秒以内的通常都是一些喘息或奇怪的音频,对训练没什么帮助。15秒以上的通常是一些长句,中间呼吸时间太短导致程序无法区分。
此时可以针对这些长音频,将间隔时间设短一些,例如100ms,再试一次。
然后再删掉4秒以内,15秒以上的音频。最后我得到467段有效音频:
四、训练模型
4.1 识别数据集和数据预处理
接下来要使用整合包里的 so-vits-svc 。
将上述得到的所有小wav文件,复制到 so-vits-svcdataset_rawartists 目录下。
双击 启动webui.bat 批处理文件:

启动后切换到训练页,点击按钮 识别数据集:
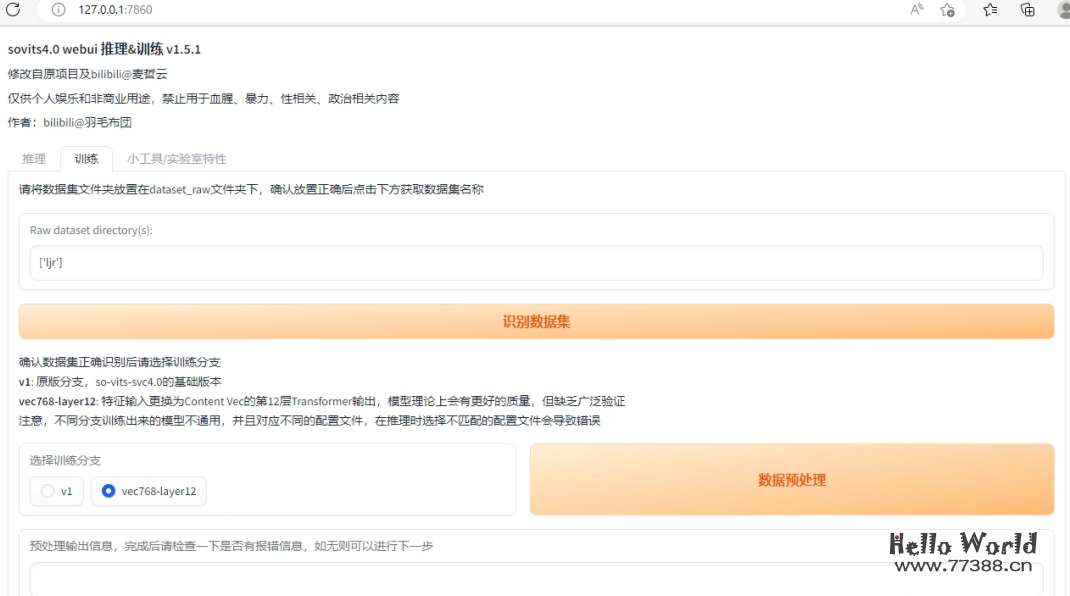
成功后训练分支选项生效,这里选择 vec768-layer12,然后点击按钮 数据预处理:

预处理非常快,大约5分钟完成。
完成后点击 写入配置文件。
4.2 训练
按下图进行参数配置。
需要注意的是,批量大小需要根据显存大小决定,8G显存可填4,据说填6也可以。
生成日志步数 200,保存模型步数 800 的意思是每次200步会生成一次日志,但并不保存模型,而重复4次即800步才保存模型。
如果你的训练经常中断,建议按这个参数就可以了。
最下面三个按钮,从头开始表示开始一次新的训练。继续上一次,表示在上述每800 step保存的模型checkpoint上继续,这个功能很常用;训练聚类模型,据说没什么差别,先不管。
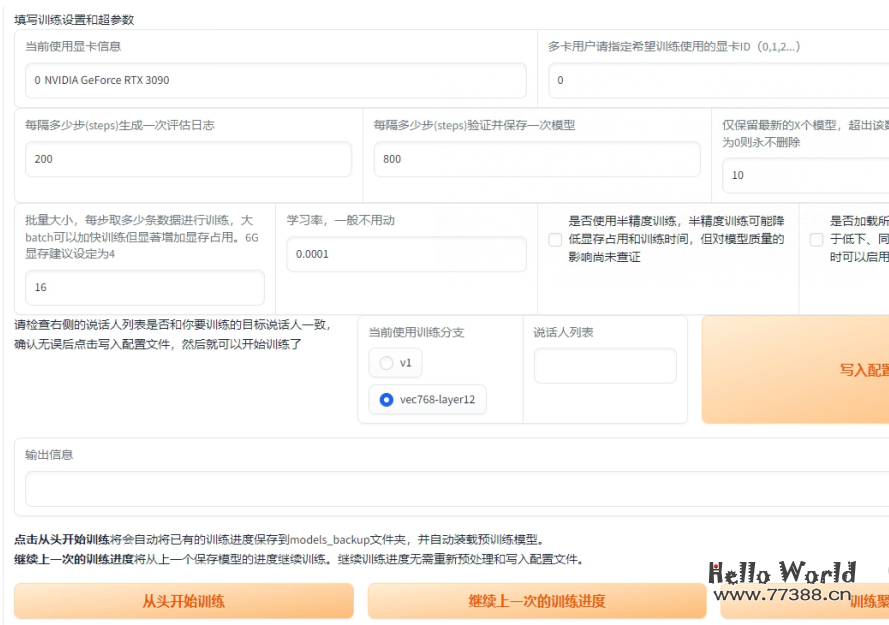
设置好参数以后,先点击 写入配置文件,界面提示成功,然后点击 从头开始训练。
系统跳出一个单独的命令行窗口,展示训练过程
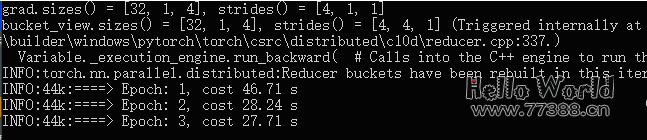
训练时间可长可短,时间越长效果超好。
通过loss可以大致判断模型状态:
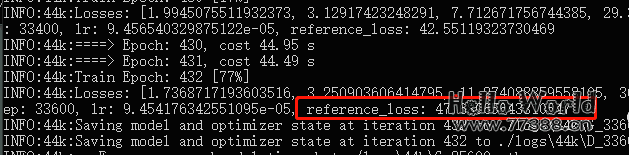
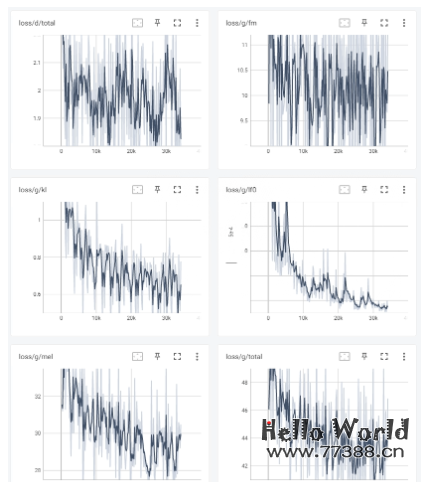
也可以使用整合包目录下的 tensorboard 来查看
![]()
url是 localhost:6006
中途中断的话,下次继续时可以点击 续续上一次训练
提醒一下,训练长达十数小时,夏天训练要注意显卡的温度,可以通过 GPU-Z 查看:
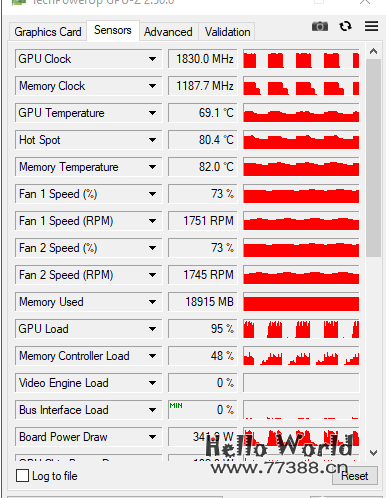
在弹出的训练窗口中点击 Ctrl+C 即可停止训练,如果 Ctrl+C 后没有停止,则可以多点几次,或者直接关闭窗口。
五、推理(音频生成)
停止训练以后,切换到推理页面。
所谓推理,就是使用模型去计算,将输入的声音变声为模型的声音。
先点击 刷新选项,程序会重载模型目录 .logs 内的模型。该目录保存着最新的X个模型,X为训练前设置的参数 仅保留最新的X个模型 。
选择 G_xxxx.pth,其中数字越大,表示迭代次数越多,但不一定效果最好。
最好的模型一般是对应 loss 最低的,但loss最低也可能是过拟合。这个根据实际情况来选择。
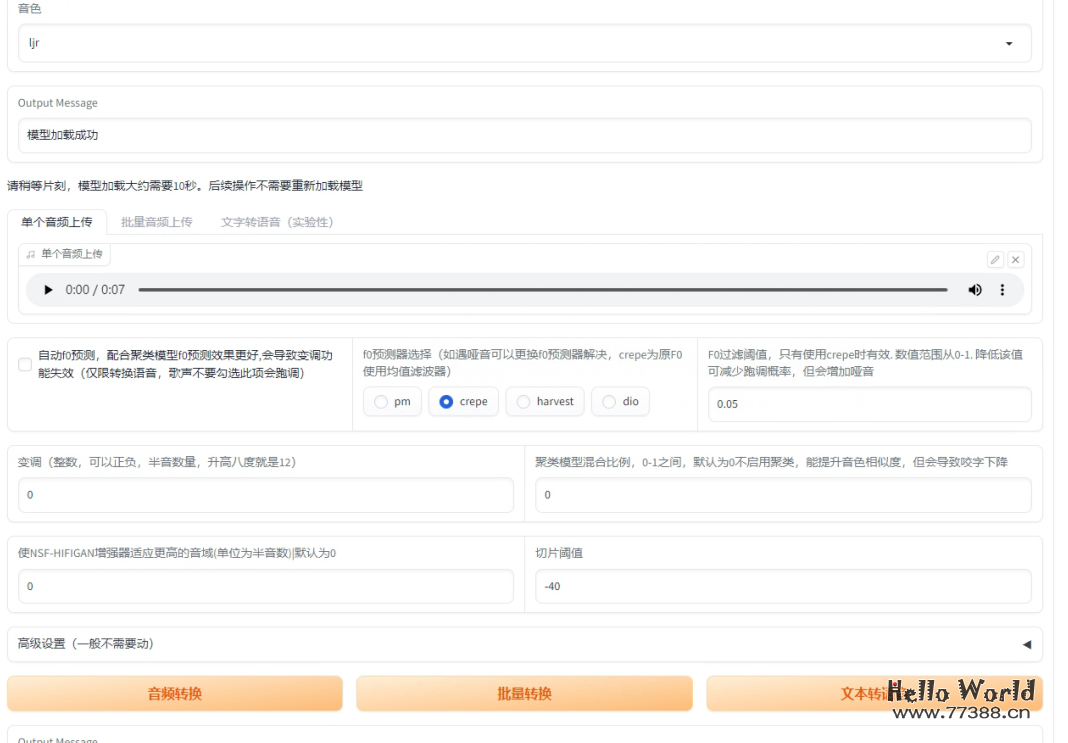
这里要注意的是,推理音频不要太长,否则会出现显存不足的情况。
我这样与前面训练时相同,将音频去掉音乐,剪切成小段然后再放上来推理,这样以方便与原声对比。
如果要得到完整的音乐,则需要再次合并。
最开头的声音是谁的,猜到了吗?
使用的软件包是整合包,需要的话在下面下载
本站资源部分来自网友投稿,如有侵犯你的权益请联系管理员或给邮箱发送邮件PubwinSoft@foxmail.com 我们会第一时间进行审核删除。
站内资源为网友个人学习或测试研究使用,未经原版权作者许可,禁止用于任何商业途径!请在下载24小时内删除!
如果遇到评论可下载的文章,评论后刷新页面点击“对应的蓝字按钮”即可跳转到下载页面!
本站资源少部分采用7z压缩,为防止有人压缩软件不支持7z格式,7z解压,建议下载7-zip,zip、rar解压,建议下载WinRAR。
温馨提示:本站部分付费下载资源收取的费用为资源收集整理费用,并非资源费用,不对下载的资源提供任何技术支持及售后服务。


