



在当今数字化时代,数据的重要性越来越凸显。在许多行业中,人们需要从网站上获取大量数据以进行分析和研究。然而,这个过程可能非常耗时费力,需要不断手动操作获取数据,容易出现错误。为了解决这个问题,使用Python编写爬虫程序是一种非常有效的方法。而使用ChatGPT作为语言模型,可以进一步简化和优化这个过程。
本文将介绍如何使用ChatGPT编写Python代码,实现网站数据的自动抓取和导出到CSV文件的功能(源文件在本文底部下载)。
我们以一个图书网站为例
使用ChatGPT逐步完成编写代码、抓取数据、自动导出的功能。
这样,我们可以更好地理解如何使用ChatGPT和Python编写爬虫程序,从而更高效地获取所需数据。
实现步骤
首先,在ChatGPT的输入框中输入以下内容,使用Python和BeautifulSoup来抓取目标网站的数据。如果您对Python很熟悉,但对BeautifulSoup不太熟悉,那么让我们简单介绍一下它。
web scrape https://books.toscrape.com/ using python and beautifulsoupBeautifulSoup是一个Python库,可以从HTML或XML文件中提取数据。
它可以通过您喜欢的转换器实现惯用的文档导航、查找和修改文档的方式。
使用BeautifulSoup可以节省数小时甚至数天的工作时间。
ChatGPT已经为我们生成了代码,如下所示:
import requestsfrom bs4 import BeautifulSoupurl = "https://books.toscrape.com/"# Send a GET request to the websiteresponse = requests.get(url)# Parse the HTML content using BeautifulSoupsoup = BeautifulSoup(response.content, "html.parser")# Find all the book titles and prices on the first pagefor book in soup.find_all("article", class_="product_pod"):title = book.h3.a["title"]price = book.select(".price_color")[0].get_text()print(title, price)
请注意,在代码开头需要导入request和BeautifulSoup库。如果您没有安装这些库,运行Python代码时会报错。您可以使用以下命令进行安装。
pip install requestspip install beautifulsoup4
安装完成后,将上面的代码复制到test.py文件中。在cmd命令行模式下输入以下命令来运行这个Python文件:
python test.py
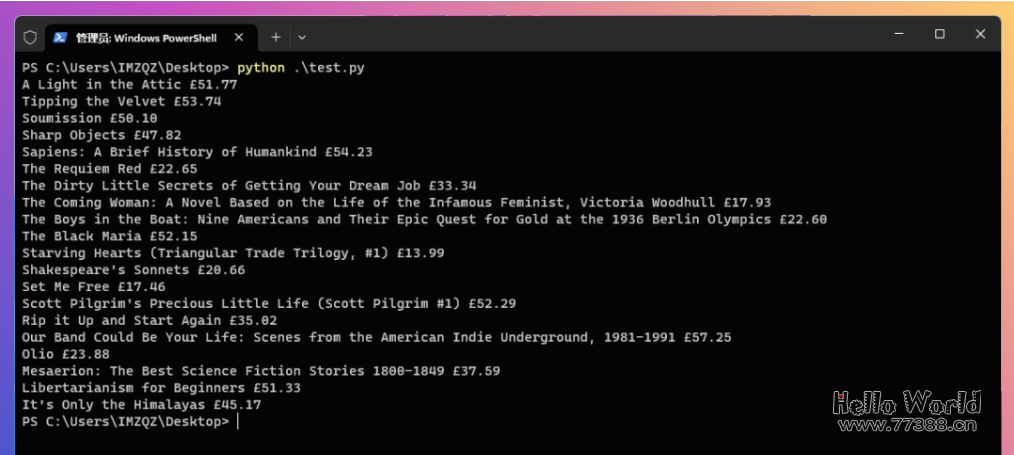
如果一切正常,您将看到返回的数据,包括“书名”和“价格”。以第一条内容为例:A Light in the Attic £51.77,其中A Light in the Attic是书名,£51.77是价格。
如果我们还想获取每本书的页面链接,该怎么办?让ChatGPT继续干活。在窗口中输入以下内容:
also scrape link to each bookChatGPT将继续编写代码,最终生成的代码如下所示:
import requestsfrom bs4 import BeautifulSoupurl = "https://books.toscrape.com/"# Send a GET request to the websiteresponse = requests.get(url)# Parse the HTML content using BeautifulSoupsoup = BeautifulSoup(response.content, "html.parser")# Find all the book titles, prices, and links on the first pagefor book in soup.find_all("article", class_="product_pod"):title = book.h3.a["title"]price = book.select(".price_color")[0].get_text()link = book.h3.a["href"]book_url = url + link.replace("../../", "")print(title,'/', price, '/', book_url)
请注意,这段代码中多了下面的两行
link = book.h3.a["href"]book_url = url + link.replace("../../", "")
保存代码后,重新执行并查看结果
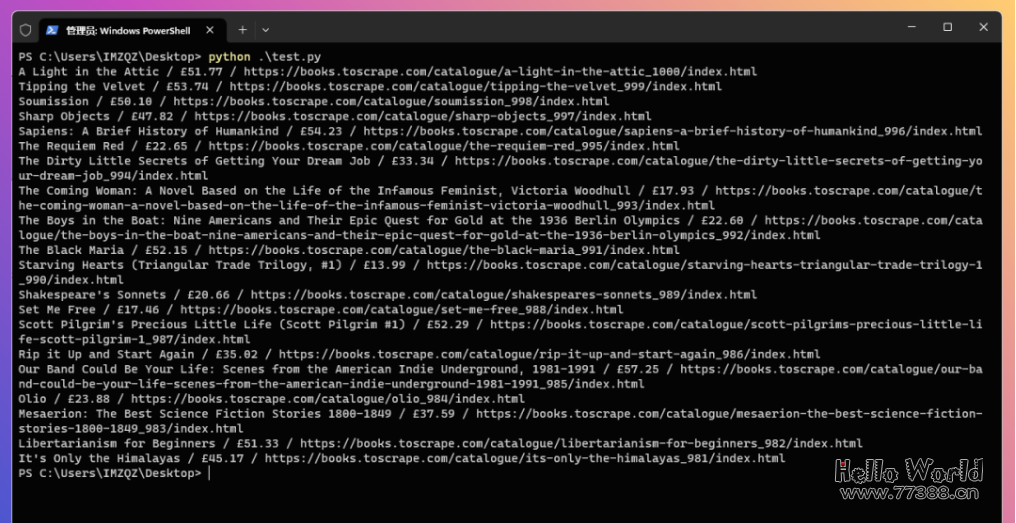
这次输出的内容使用/将三个字段进行了区分:标题/价格/链接。
看起来还不错。有了这些数据基础,我们下一步来尝试将生成的内容自动导出为CSV文件。
在ChatGPT的窗口中输入以下内容::
export data to csv fileChatGPT又开始写代码,最后输出结果如下:
import csvimport requestsfrom bs4 import BeautifulSoupurl = "https://books.toscrape.com/"# Send a GET request to the websiteresponse = requests.get(url)# Parse the HTML content using BeautifulSoupsoup = BeautifulSoup(response.content, "html.parser")# Create a CSV file and write the headerswith open("book_data.csv", "w", newline="") as file:writer = csv.writer(file)writer.writerow(["Title", "Price", "URL"])# Find all the book titles, prices, and links on the first pagefor book in soup.find_all("article", class_="product_pod"):title = book.h3.a["title"]price = book.select(".price_color")[0].get_text()link = book.h3.a["href"]book_url = url + link.replace("../../", "")writer.writerow([title, price, book_url])
这段新生成的代码,多出了创建csv文件的内容:
# Create a CSV file and write the headerswith open("book_data.csv", "w", newline="") as file:writer = csv.writer(file)writer.writerow(["Title", "Price", "URL"])
保存运行,你会发现,运行报错,意思就是GBK不行,那怎么办?
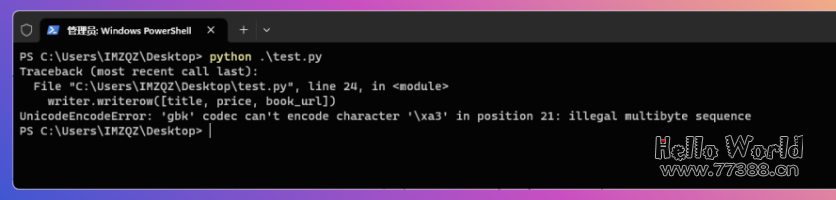
那只能再劳烦ChatGPT了,输入以下内容:
use utf8 encoder让它使用utf8的编码进行导出csv,得到以下代码
import csvimport requestsfrom bs4 import BeautifulSoupurl = "https://books.toscrape.com/"# Send a GET request to the websiteresponse = requests.get(url)# Parse the HTML content using BeautifulSoupsoup = BeautifulSoup(response.content, "html.parser")# Create a CSV file and write the headerswith open("book_data.csv", "w", newline="", encoding="utf-8") as file:writer = csv.writer(file)writer.writerow(["Title", "Price", "URL"])# Find all the book titles, prices, and links on the first pagefor book in soup.find_all("article", class_="product_pod"):title = book.h3.a["title"]price = book.select(".price_color")[0].get_text()link = book.h3.a["href"]book_url = url + link.replace("../../", "")writer.writerow([title, price, book_url])
可以看到,代码中加入了对编码格式的要求
with open("book_data.csv", "w", newline="", encoding="utf-8") as file:运行看看结果,这次就很完美了,没有任何报错和反馈,这代表文件已经生成完毕。

快!快!快!打开CSV文件看看效果。漂亮!
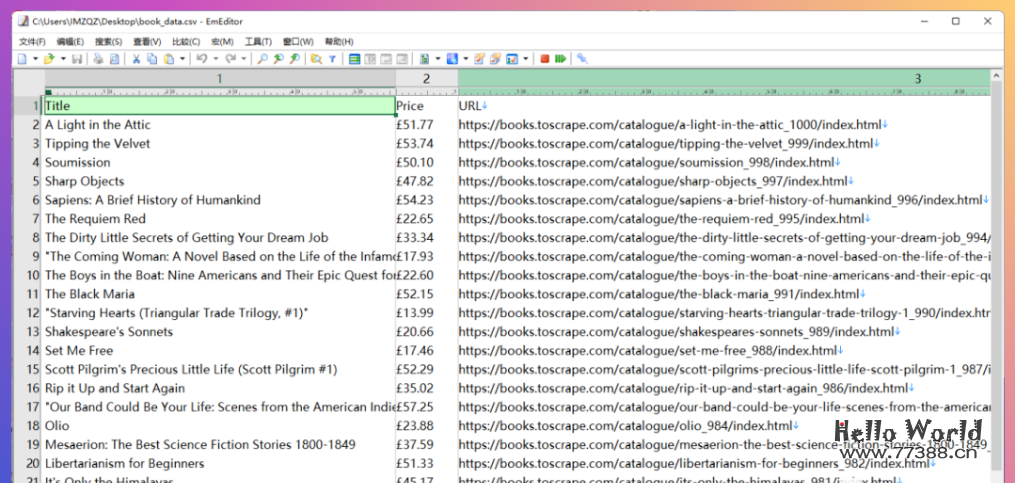
使用ChatGPT编写Python代码可以大大简化和优化爬虫程序的编写过程,实现自动抓取网站数据并导出CSV文件的功能。
本文将介绍使用ChatGPT编写爬虫程序的基本步骤,并提供实用的代码示例。
同时,我们强调在进行网络数据抓取时需要遵守相关法律法规,尊重网站所有者的权益,避免对网站造成不必要的麻烦。
希望本文能够帮助您学习和掌握Python编程和网络爬虫技术,并在使用ChatGPT进行自然语言生成方面提供启示。
本站资源部分来自网友投稿,如有侵犯你的权益请联系管理员或给邮箱发送邮件PubwinSoft@foxmail.com 我们会第一时间进行审核删除。
站内资源为网友个人学习或测试研究使用,未经原版权作者许可,禁止用于任何商业途径!请在下载24小时内删除!
如果遇到评论可下载的文章,评论后刷新页面点击“对应的蓝字按钮”即可跳转到下载页面!
本站资源少部分采用7z压缩,为防止有人压缩软件不支持7z格式,7z解压,建议下载7-zip,zip、rar解压,建议下载WinRAR。
温馨提示:本站部分付费下载资源收取的费用为资源收集整理费用,并非资源费用,不对下载的资源提供任何技术支持及售后服务。


