


Stable Diffusion是一个重要的AI图像生成模型,其发布标志着AI文本图片生成技术变得更加普及化和易用化。最近,一些人利用该模型对真实人物的图片进行训练,生成的结果足以以假乱真,很难分辨是AI生成还是真实拍摄。如果你对此感兴趣,本文将从头开始教你如何构建一个真人AI网站。本教程分5个目录帮助大家学习搭建本地化Midjourney(Stable Diffusion)
1. 搭建自己的AI网站2. 模型下载安装3. 汉化插件下载安装4. 生成模拟真人图片4.1 生成模拟真人图片4.2 不同风格图片生成4.3 动画视频生成5. 生成的图片开口说话
01:搭建自己的AI网站
第一步,我们可以直接使用 GitHub 仓库:
stable-diffusion-webui

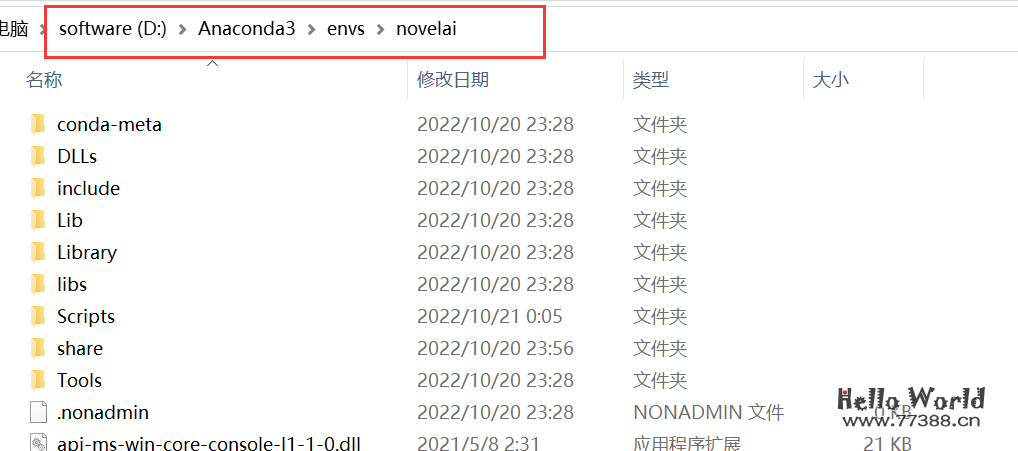
第一步,在你的电脑上安装 python环境,版本 3.10.6,如果已经安装了其他 python 版本,可以利用 conda
安装3.10 的虚拟环境版本:
conda create -n novelai python==3.10.6
下载仓库代码:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
https://pytorch.org/get-started/locally/
./python -m pip install torch torchvision torchaudio --extra-index-url https://download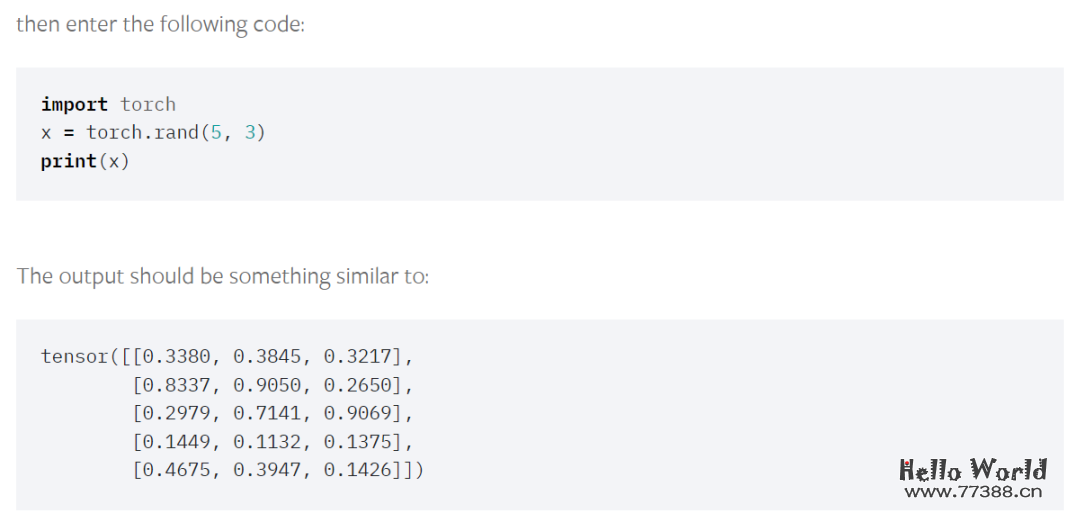
python -m pip install -r requirements.txt02:模型下载安装
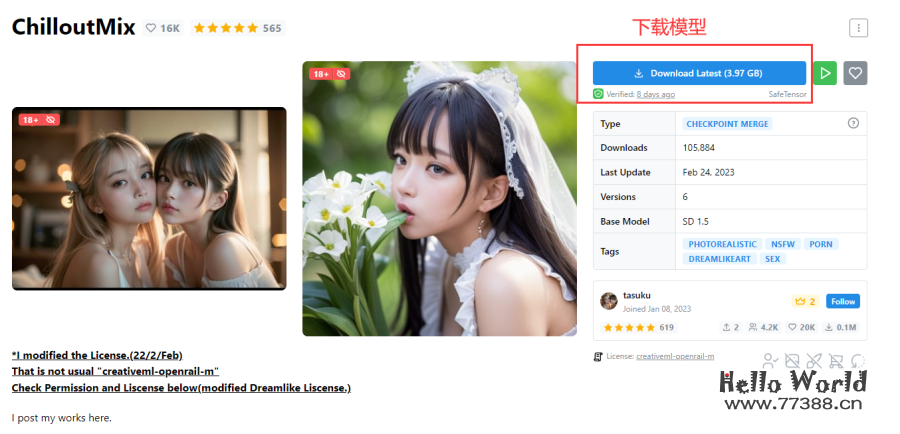
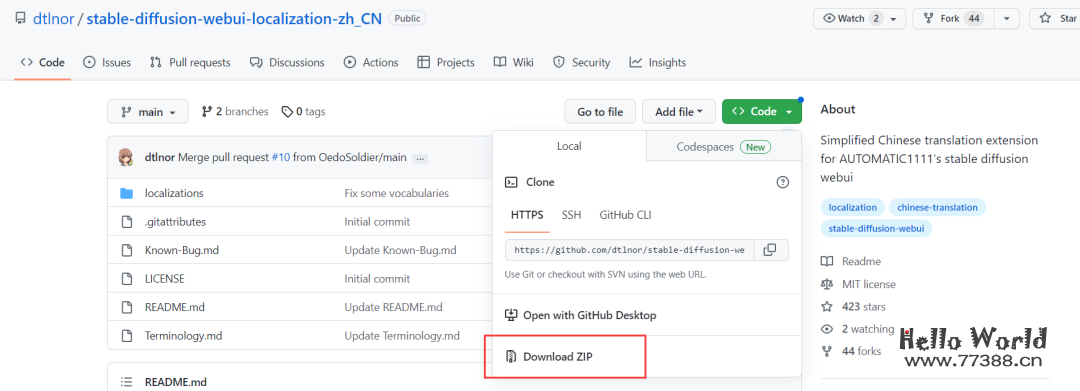
https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN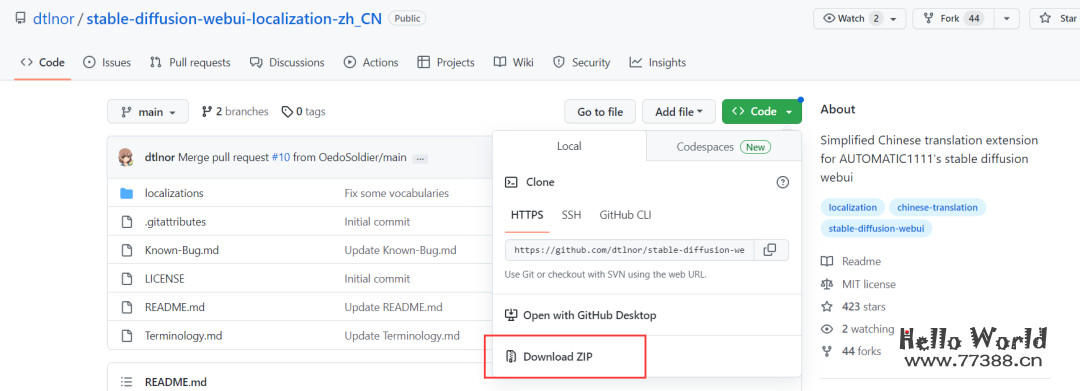
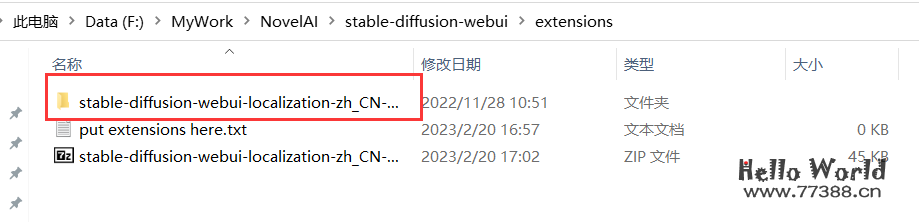
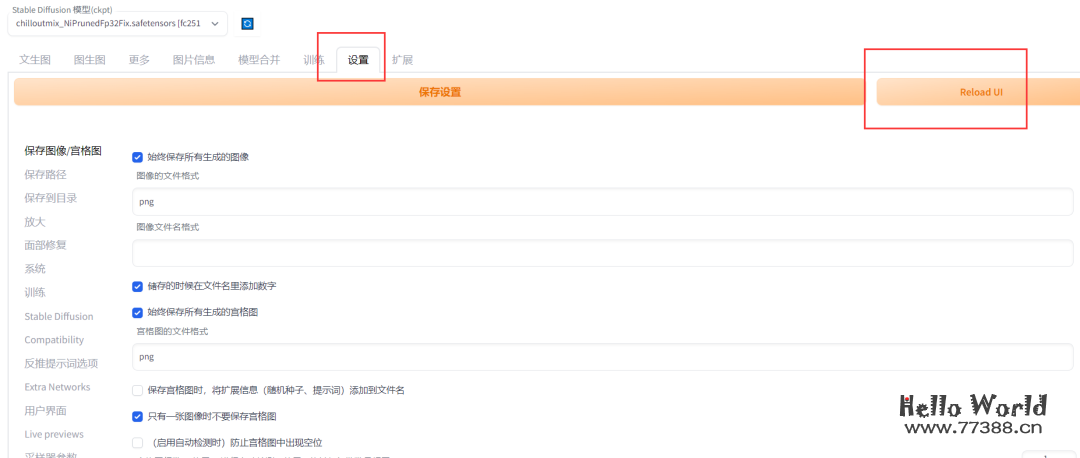
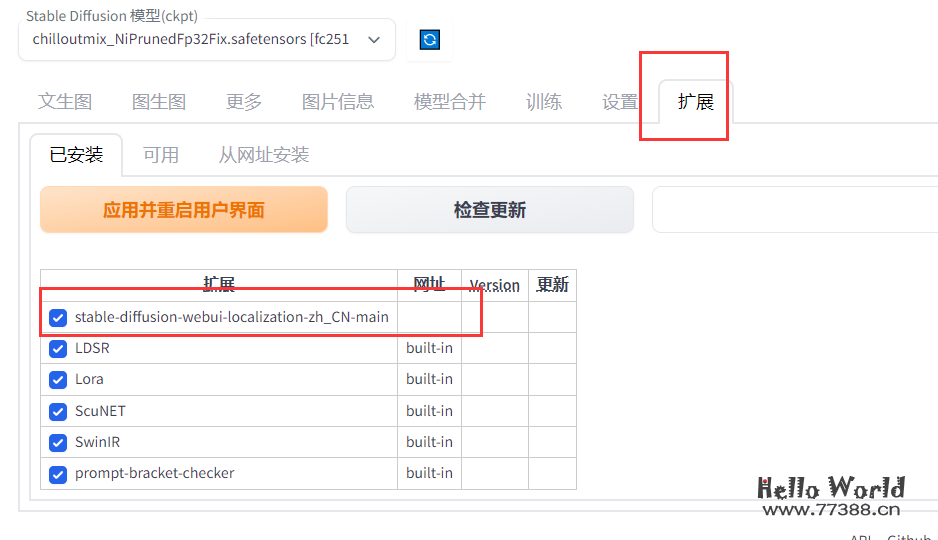

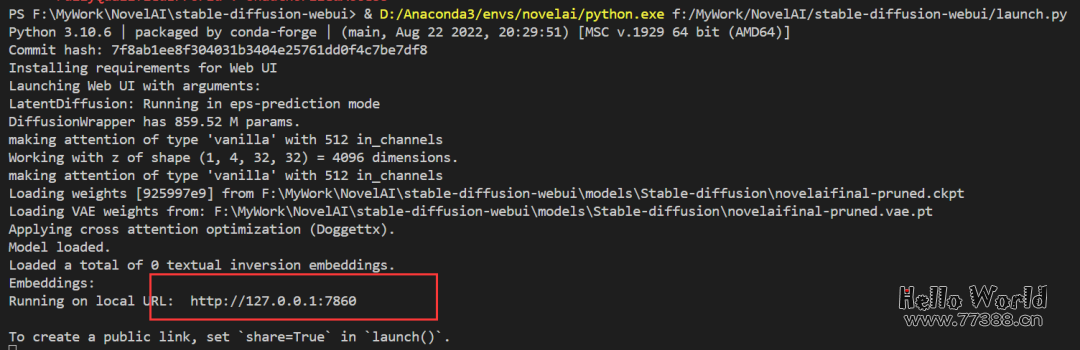
4.1 生成模拟真人图片

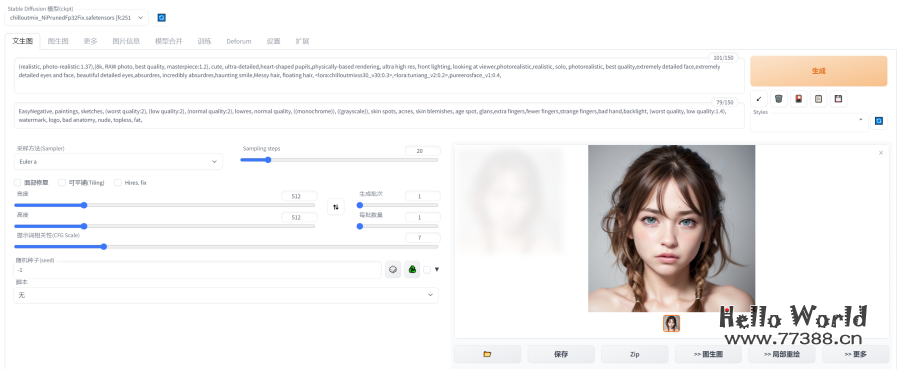
4.2 不同风格图片生成
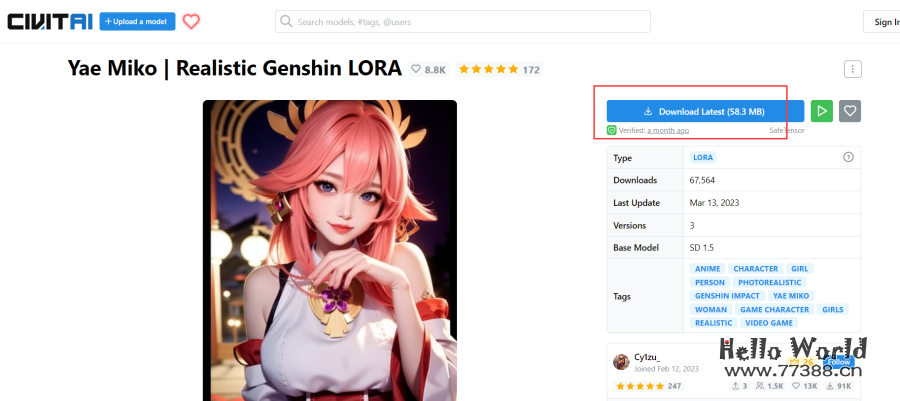
在 https://civitai.com/上,还有很多 Lora 模型可以进行下载。这是一种可以帮助你调整画风的小模型。主要是放到 Prompt 中进行使用。例如我们可以在网站上下载原神的 Lora 模型:

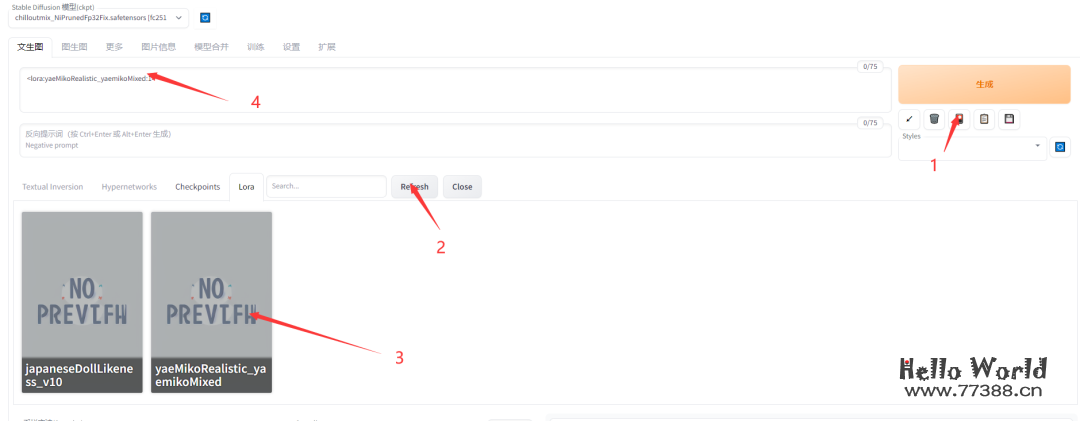
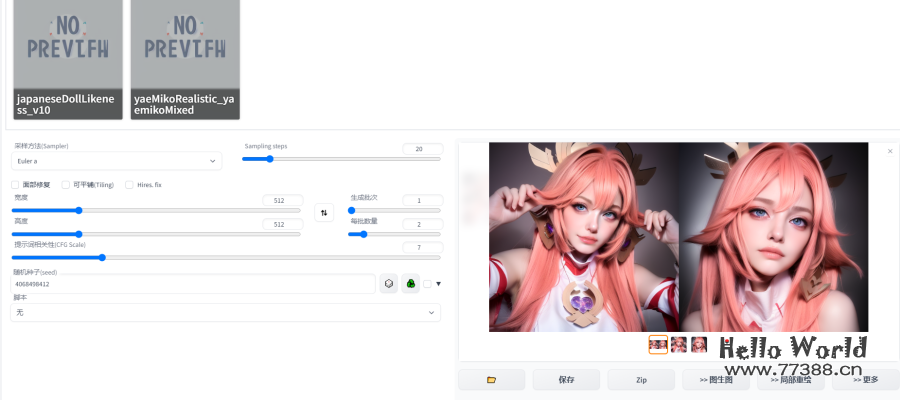
4.3 动画视频生成
https://github.com/deforum-art/deforum-for-automatic1111-webuigit clone https://github.com/deforum-art/deforum-for-automatic1111-webui extens
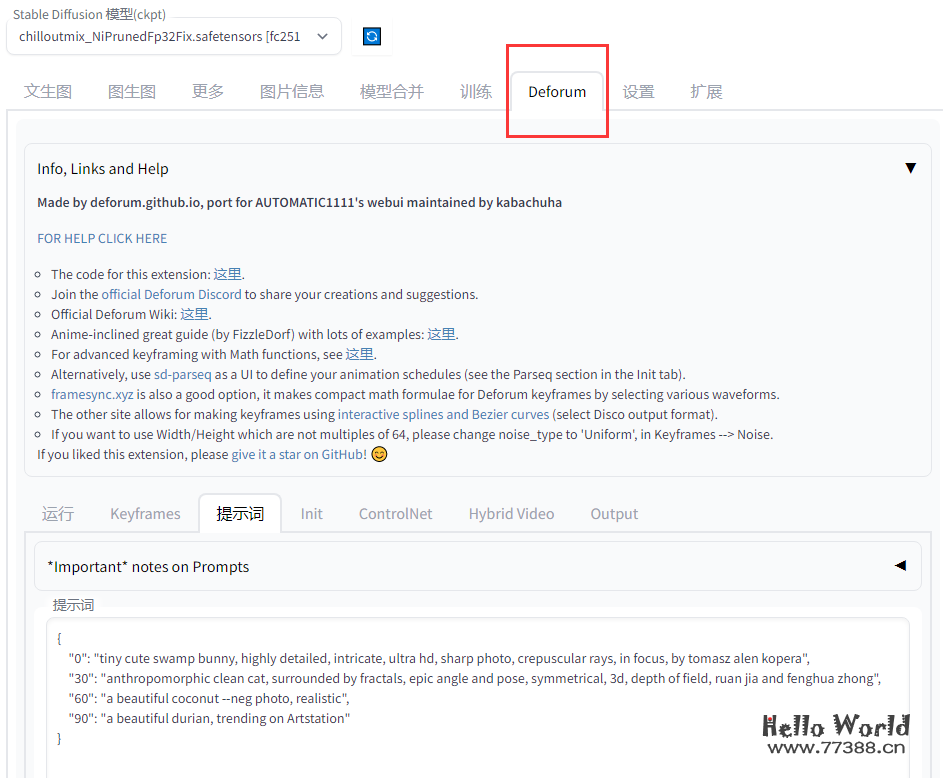
{ "0": "tiny cute swamp bunny, highly detailed, intricate, ultra hd, sharp photo, crepuscular rays, in focus, by tomasz alen kopera", "30": "anthropomorphic clean cat, surrounded by fractals, epic angle and pose, symmetrical, 3d, depth of field, ruan jia and fenghua zhong", "60": "a beautiful coconut --neg photo, realistic", "90": "a beautiful durian, trending on Artstation"}
//Abstracted Example{ "0": "Prompt A --neg NegPompt" "12": "Prompt B" }其中“0”和“12”提示在插值中解析的关键帧。Prompt A 和 B 是肯定提示,NegPrompt 是否定提示。当然,也可以直接用上面 C 站下载下来的模型,

05:生成的图片开口说话








Midjourney Prompt 关键词的语法结构 & 用后缀参数控制出图比例
本站资源部分来自网友投稿,如有侵犯你的权益请联系管理员或给邮箱发送邮件PubwinSoft@foxmail.com 我们会第一时间进行审核删除。
站内资源为网友个人学习或测试研究使用,未经原版权作者许可,禁止用于任何商业途径!请在下载24小时内删除!
如果遇到评论可下载的文章,评论后刷新页面点击“对应的蓝字按钮”即可跳转到下载页面!
本站资源少部分采用7z压缩,为防止有人压缩软件不支持7z格式,7z解压,建议下载7-zip,zip、rar解压,建议下载WinRAR。
温馨提示:本站部分付费下载资源收取的费用为资源收集整理费用,并非资源费用,不对下载的资源提供任何技术支持及售后服务。


