



大语言模型中,向来都只有ChatGPT以及其他。而由前 OpenAI副总裁离职创建的Claude,借着100k上下文成功出圈了,在无需微调的情况下,可以喂进整本书直接进行提问。这说明了长上下文,是大模型一个有效的突破点。
Salesforce就在昨天,一口气开源了三个模型,分别是:XGen-7b 8k base, XGen-7b 7k inst, XGen-7b 4k base。
这三个模型采用了比 LLaMA-7b 更宽松的开源协议 Apach2,主要就是允许商用。
目前为止,大多数开源模型为了能让用户在低资源的硬件上能使用,普遍走的路线都是减少参数规模,主要集中在6b-13b这个区间。
一旦超过13b这个数量,普通消费级的显卡就无法运行,大大限制了模型的普及应用。
在6b-13b这个区间的模型无法全方位与ChatGPT进行竞争,一般走的路线是强化细分领域的应用,在用户微调后,在某个细分领域,能无限接近甚至超越ChatGPT。
Salesforce此次开源的XGen-7b的长上下文,主要针对的应用领域是文本总结、代码生成、蛋白质序列预测等。
| Model | Description |
|---|---|
| XGen-7B-4K-base | 使用8千亿长度为2k的token训练,然后再训练长度为4k的4000亿个token,共1.2万亿Token |
| XGen-7B-8K-base | 基于 XGen-7b 4k,再增加3000亿个长度为8k的序列,共1.5万亿Token |
| XGen-7B-{4K,8K}-inst | 监督公共领域教学数据的微调,包括databricks-dolly-15k, oasst1, Baize and GPT-related datasets。仅供研究之用。 |
数据集
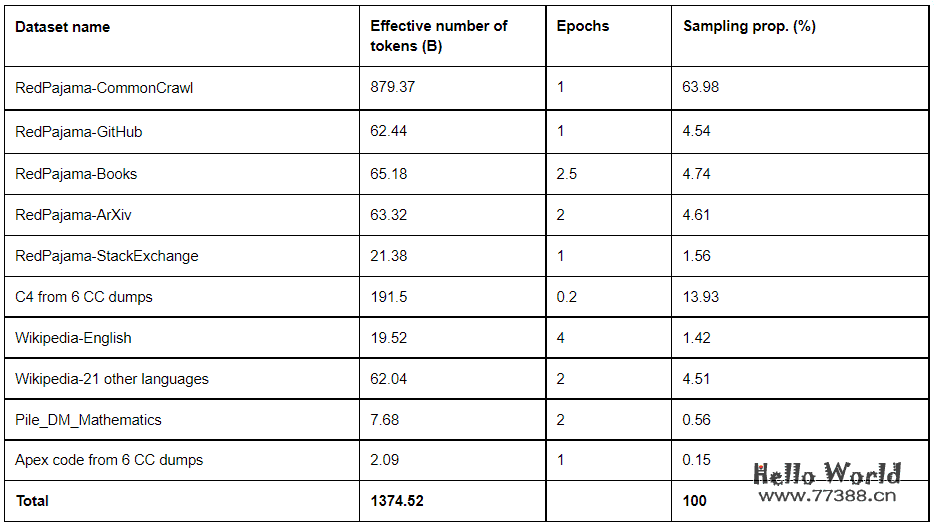
数据集包含中文在内的22种语言,多于LLaMA的20种语言。意味着这个模型中文表现应该会不错。
而XGen-7b并没有采用ChatGPT的数据集,这导致其在某些能力与ChatGPT有明显差异。
XGen-7b 训练硬件是 TPU-v4而不是GPU,这与Google的PaLM2相同。并且使用了Salesforce内部的Jax进行训练(名字听起来就很NB),在 github上可以找到 salesforce/jaxformer 库,但这个可能不是最新的版本。所以XGen-7b训练速度很快,也意味着更低的训练成本(1万亿Token 15万美元)。。
模型效果
XGen-7b 已经完成了一些基准测试,从公布的测试结果看,XGen-7b 目前在MMLU 5 shot和0 shot下的整体得分,都优于其他开源模型。
MMLU 5-shot In-context Learning Results
| Models | Humanities | STEM | Social Sciences | Other | Weighted average |
|---|---|---|---|---|---|
| XGen-7b | 33.8 | 30.7 | 40.0 | 41.5 | 36.3 |
| LLaMA-7b | 33.9 | 30.6 | 38.2 | 38.2 | 35.1 |
| OpenLLaMA-7b | 28.1 | 28.5 | 31.2 | 32.8 | 29.9 |
| Falcon-7b | 26.5 | 25.4 | 29.2 | 26.8 | 26.9 |
| MPT-7b | 25.9 | 26.2 | 26.9 | 28.1 | 26.7 |
| Redpajama-7b | 26.1 | 25.2 | 27.4 | 26.7 | 26.3 |
| Cerebras-GPT-13b | 26.1 | 26.5 | 25.8 | 26.6 | 26.2 |
| Dolly-v2-12b | 26.9 | 25.7 | 25.3 | 26.5 | 26.2 |
| OPT-13b | 26.2 | 24.3 | 23.4 | 26 | 25.1 |
| GPT-J-6b | 25.9 | 24.0 | 24.0 | 25.8 | 25.1 |
MMLU 0-shot Results:
| Models | Humanities | STEM | Social Sciences | Other | Weighted average |
|---|---|---|---|---|---|
| XGen-7b | 31.4 | 27.8 | 32.1 | 37.2 | 32.1 |
| LLaMA-7b | 32.3 | 27.1 | 31.3 | 36.8 | 32.0 |
| OpenLLaMA-7b | 28.0 | 27.6 | 28.9 | 30.1 | 28.6 |
| MPT-7b | 27.4 | 25.2 | 26.0 | 30.7 | 27.4 |
| Redpajama-7b | 27.5 | 25.5 | 24.2 | 25.0 | 25.8 |
| GPT-J-6b | 25.3 | 24.5 | 25.5 | 27.6 | 25.7 |
| Dolly-v2-12b | 26.2 | 26.0 | 24.0 | 24.9 | 25.4 |
| Cerebras-GPT-13b | 24.3 | 25.0 | 23.0 | 26.0 | 24.6 |
| OPT-13b | 26.3 | 25.3 | 23.6 | 23.6 | 24.4 |
| Falcon-7b | 24.8 | 21.7 | 24.0 | 24.4 | 23.9 |
但是在General Zero-shot测试下,Hella Swag数据集的结果要差于其他模型。
在编程领域,XGen-7b优于LLaMA,但弱于 MPT-7b。这与他声称的目标还有点距离。
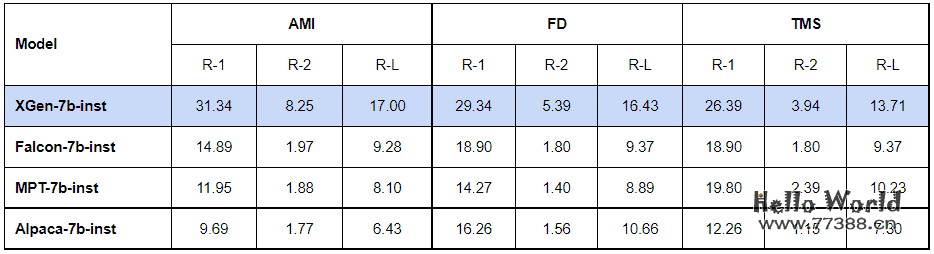
最后,在长文本领域,XGen-7b明显优于其他模型。
采用开源模型开发的知识库项目众多,但实测下来都会发现实用性有限,有时还真不如自己看文档来得快。更甚的是一些回答会出错,这让人对他的每一次回答都产生怀疑。还很难说具有实用性。
知识库除去分词准确性及矢量数据库所抓取的长度因素外,最重要就是大模型对长文本的理解能力。而XGen-7b出色的长文本摘要能力,有机会将一众知识库能力向上拨高一个层级。
但是,从整体来看,XGen-7b 并没有与其他模型拉开很大的距离。
安装
目前 XGen-7b 已将模型上传到 huggingface,并且在github提供了简单的安装和应用示例:
pip install tiktoken
推理
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/xgen-7b-8k-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Salesforce/xgen-7b-8k-base", torch_dtype=torch.bfloat16)
inputs = tokenizer("The world is", return_tensors="pt")
sample = model.generate(**inputs, max_length=128)
print(tokenizer.decode(sample[0]))
本站资源部分来自网友投稿,如有侵犯你的权益请联系管理员或给邮箱发送邮件PubwinSoft@foxmail.com 我们会第一时间进行审核删除。
站内资源为网友个人学习或测试研究使用,未经原版权作者许可,禁止用于任何商业途径!请在下载24小时内删除!
如果遇到评论可下载的文章,评论后刷新页面点击“对应的蓝字按钮”即可跳转到下载页面!
本站资源少部分采用7z压缩,为防止有人压缩软件不支持7z格式,7z解压,建议下载7-zip,zip、rar解压,建议下载WinRAR。
温馨提示:本站部分付费下载资源收取的费用为资源收集整理费用,并非资源费用,不对下载的资源提供任何技术支持及售后服务。


