



如何用经济友好、内存节约的方式,来实现 LLM 生成能力和指令遵循能力的跨语言迁移?
LLM 通常基于大规模语料训练知识表示与语言生成能力,随后在人工编写的指令数据上进行微调以实现与人类的意图对齐。因此,如何有效地进行指令微调使大型语言模型对齐人类偏好,对于模型的最终性能与用户体验至关重要。
现有研究在预训练和指令微调阶段使用的数据大多仅围绕英文组成,语言的不平衡现象成为了制约模型能力以及交互体验的主要瓶颈。然而,将各个语言分别引入预训练以及指令微调阶段是昂贵且低效的。
近期,中国科学院计算技术研究所冯洋研究员带领的自然语言处理团队针对这个问题探索了新的方案 —— 在指令微调阶段将英语与其他语言对齐,以交互式翻译任务为核心进行指令微调训练。

- 项目及源码地址见本文末
基于所提方法,研究团队在中科南京信息高铁研究院的算力和工程开发团队支持下,在中科院计算所信息高铁 Al 训练推理平台 MLOps 上训练并发布了新的大型语言模型「百聆」,旨在让大型语言模型对齐人类意图的同时,将其生成能力和指令遵循能力从英语泛化到其他语种。「百聆」以经济友好、内存节约的方式实现了多语言人机交互能力。
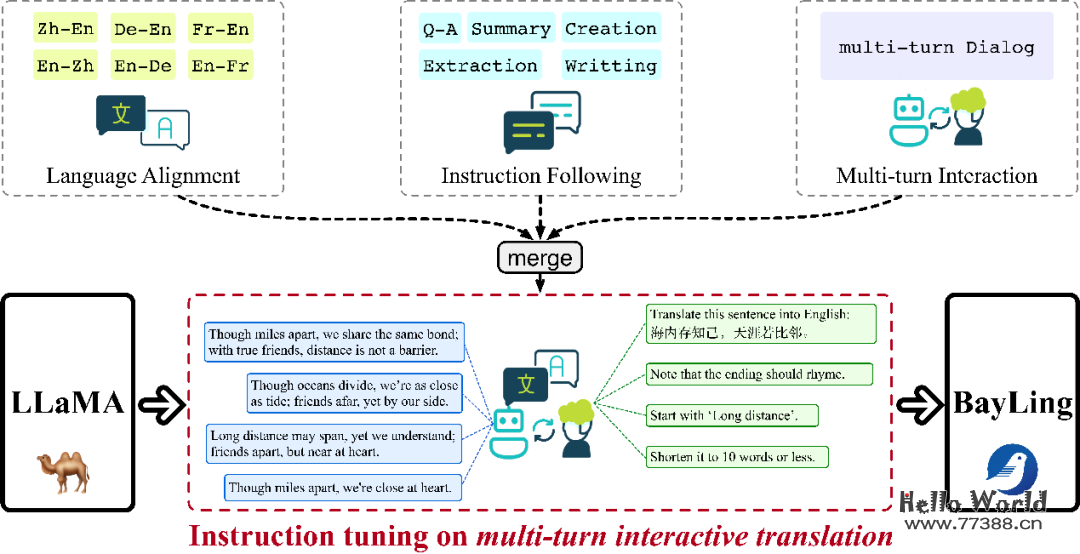
在交互式翻译任务中,研究团队通过一系列的交互向百聆提供涵盖中、英、德、法四门语言翻译相关的指令和约束条件,要求它必须在理解所有先前指令的基础上提供满足需求的反馈。借助于翻译任务的语义对齐特性,百聆能够实现生成能力在不同语言之间的迁移,并在交互式的过程中学习与人类意图进行对齐。

基于百聆-7B 和百聆-13B 的相关实验结果表明:在单轮翻译任务上,百聆达到了 GPT-4 95% 的性能,在交互式翻译上,百聆达到了 GPT-3.5-turbo 96% 的性能。
此外,研究团队还构建了双语多轮通用测试集 BayLing-80。在 BayLing-80 测试集上,百聆达到了 GPT-3.5-turbo 89% 的性能。在中文高考和英语标准化考试(SAT/GRE/GMAT等)任务上,百聆在众多大模型中位列第 2,仅次于 GPT-3.5-turbo。
出色完成各类任务
目前,研究团队已经开源了 7B 和 13B「百聆」模型权重以及 BayLing-80 双语多轮通用测试集,同时在中科南京信息高铁研究院的支撑下完成了「百聆」的线上部署,目前已经以邀请的方式开放内测。

我们来看一下「百聆」在交互式翻译、知识问答、文案写作、逻辑推理、生成与解释代码、数学计算和角色扮演多个任务上的实际表现。
交互式翻译
衡量大语言模型跨语言对齐能力的一个重要标志是其完成翻译任务的水平。百聆模型以交互式翻译任务为核心进行了指令微调训练,因此百聆在翻译方面性能优异。
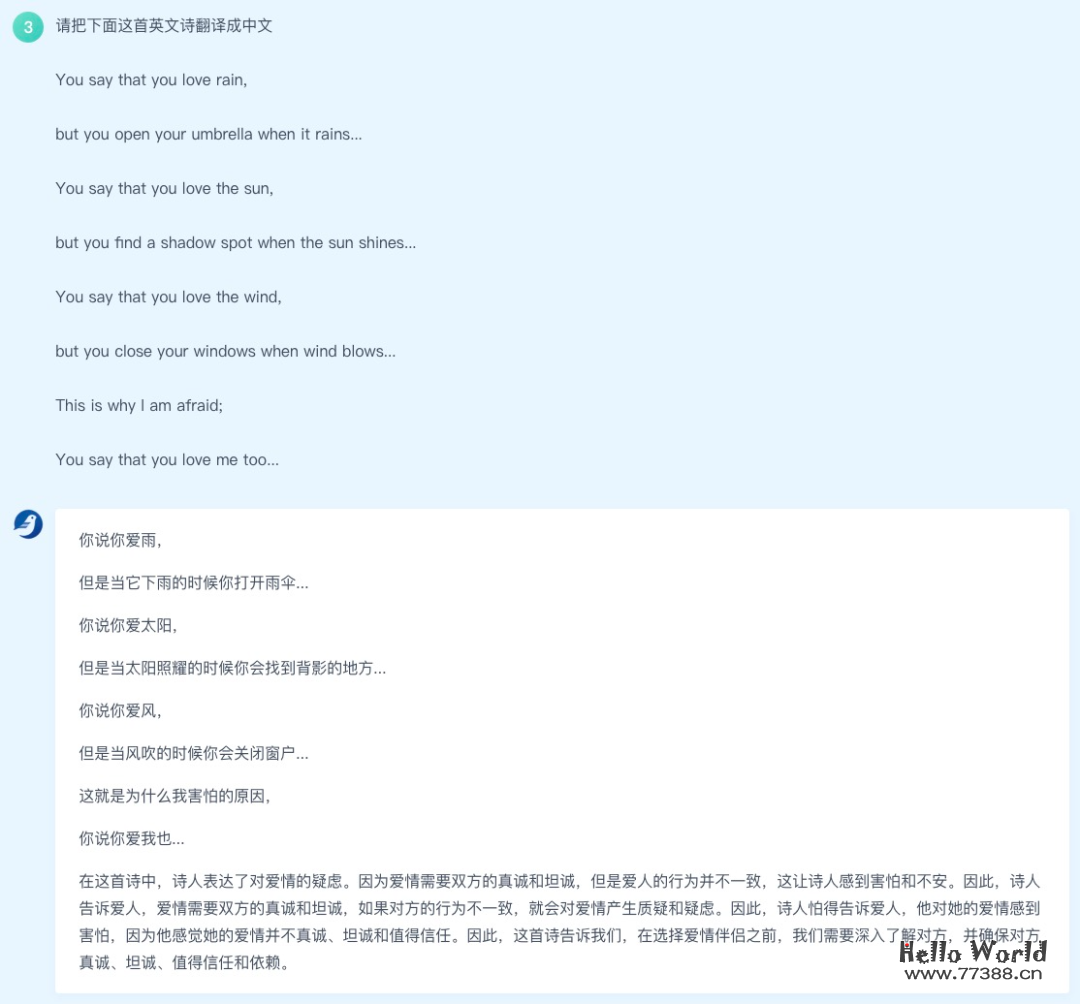
例如,百聆可以将英文诗歌翻译成中文,语言优美,饱含感情,并且可以分析提炼诗歌的主旨大意:
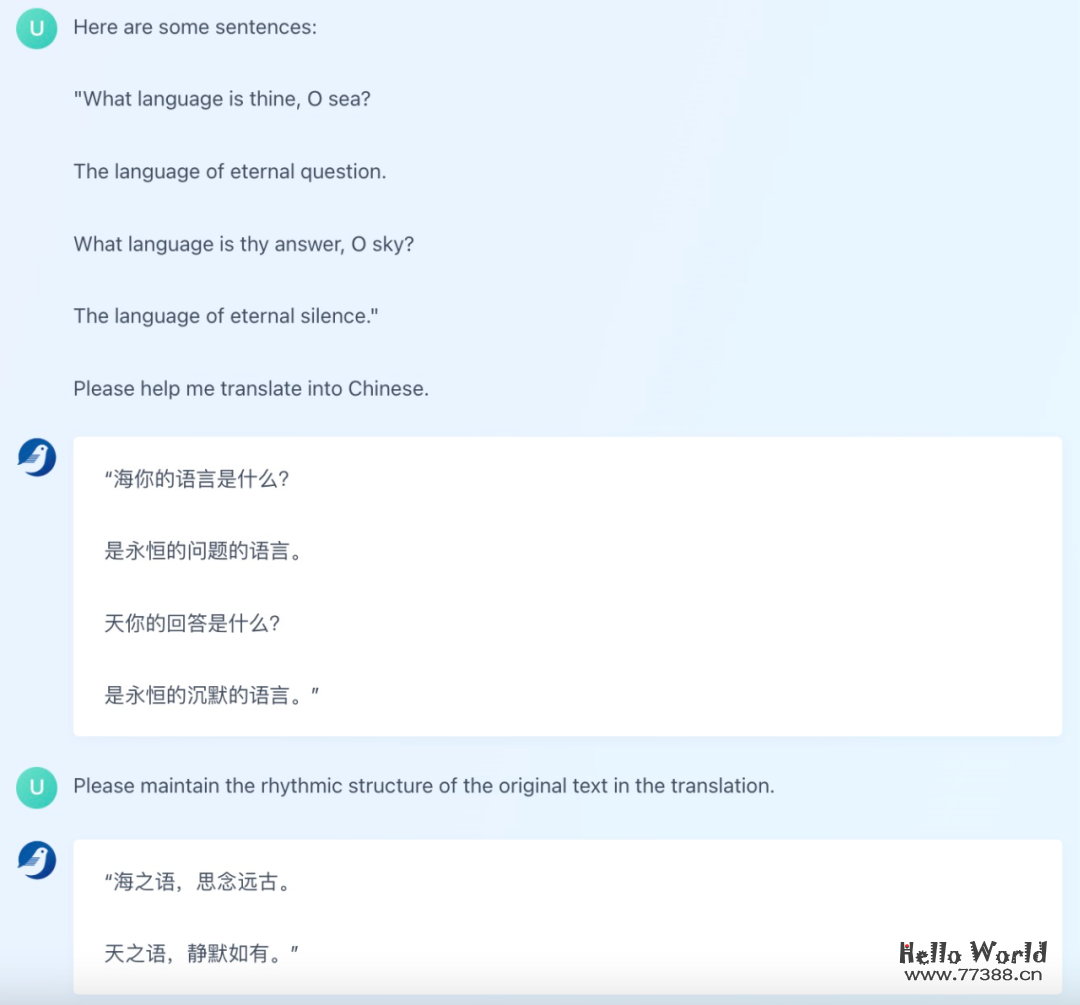
除了常规的翻译任务以外,百聆还支持用户通过额外的自然语言指令交互来约束或调整翻译结果。有些英文诗歌直译之后缺乏节奏感,用户可以让百聆模型修改翻译结果:
当然,将中文翻译成英文也是可以的,例如翻译经典的《再别康桥》:
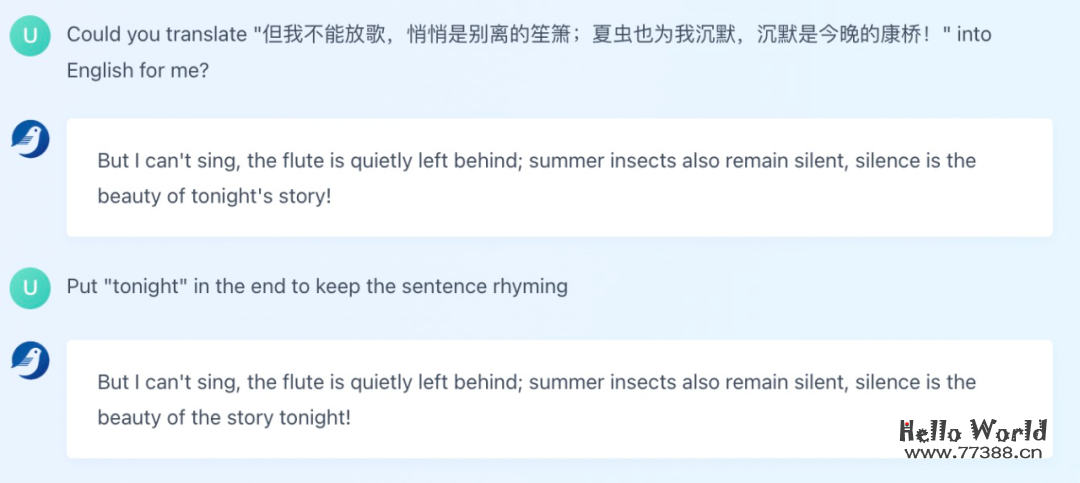
交互式的翻译体验让用户能按照自己的意图得到翻译结果。
知识问答
大型语言模型备受关注的一个重要原因是它们展现出「了解知识」的能力,包括常识和复杂知识。首先,我们看下百聆对日常问题「如何确定一个人是真正对谈话感兴趣还是只是礼貌地说话」给出的答案:

百聆的回答和我们实际生活中的分析方法基本一致,甚至更加全面。
对于更复杂的问题「解释量子计算的基础」,百聆也能给出大致回答,并且在进一步提问「这种方式相比于传统计算的优势」时,百聆给出了条理清晰的答案,这也说明它具备多轮问答能力。

文案写作
作为语言模型,文本生成是百聆模型的一项基本能力,我们实际测试了百聆的应用文案写作水平,要求它为机器之心写一则招聘广告:

生成结果基本满足我们的需求,简单修改一下就能直接用了。
另外,百聆还可以撰写简单的电子邮件,这类文案写作能力使百聆具备办公应用的潜力。

逻辑推理
在机器学习领域,逻辑推理是一项非常困难的任务。也正因为如此,大型语言模型表现出的推理能力才让人们印象深刻。
我们发现百聆大模型具备逻辑推理能力。例如,面对问题:「一个典型的冬天会下多少雪花」,百聆模型给出了下雪的影响因素,并阐述了雪的形成原理,最后给出了估计下雪量的参考条件,强调要根据实际情况分析这个问题。

当然,作为一个语言模型,逻辑推理的结果未必是完全正确的。如果我们要求百聆模型证明推理是正确的,它会诚实地回答道:「我的回答仅为一个估计,可以为读者提供一些参考,但不能保证准确性。」

生成与解释代码
由于编程代码要求符合逻辑、严谨、可执行,因此生成代码对 LLM 来说也是一项非常有挑战性的任务。我们用「找出一组数中最大数」这个经典问题测试了百聆生成代码的能力,百聆生成的代码基本正确,并且还给出了这段代码的解释。
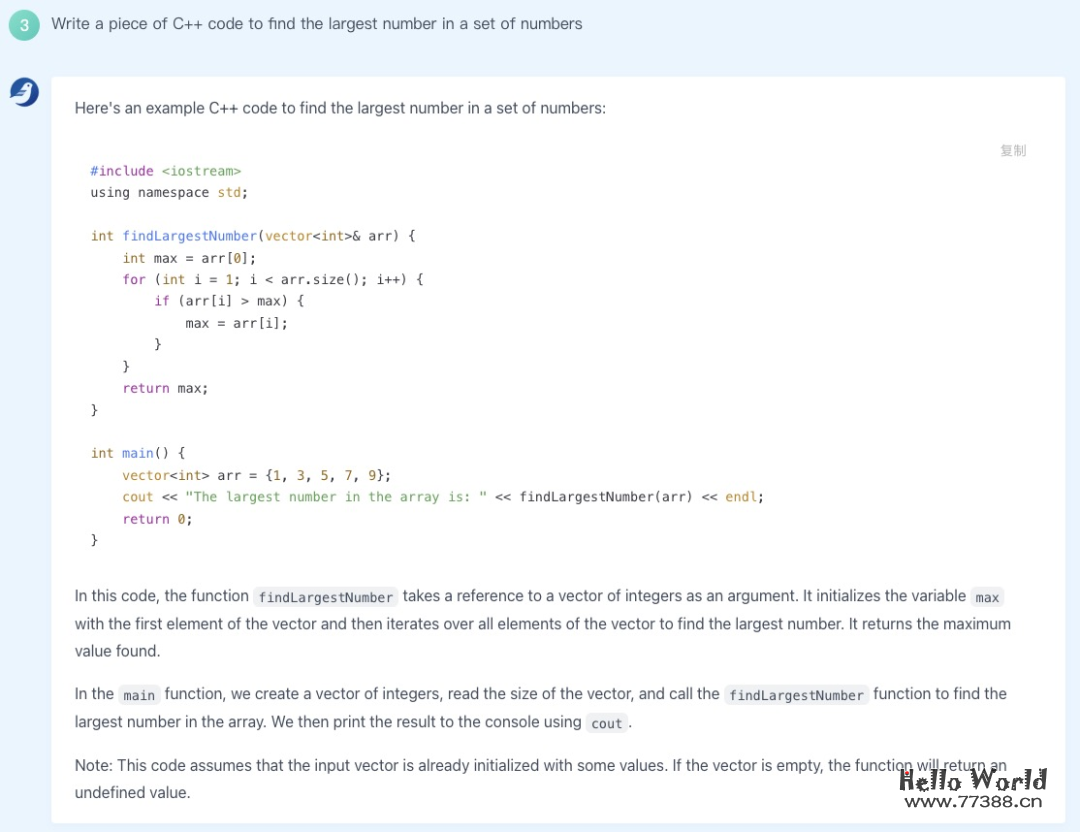
当然,你也可以用中文描述编程需求:
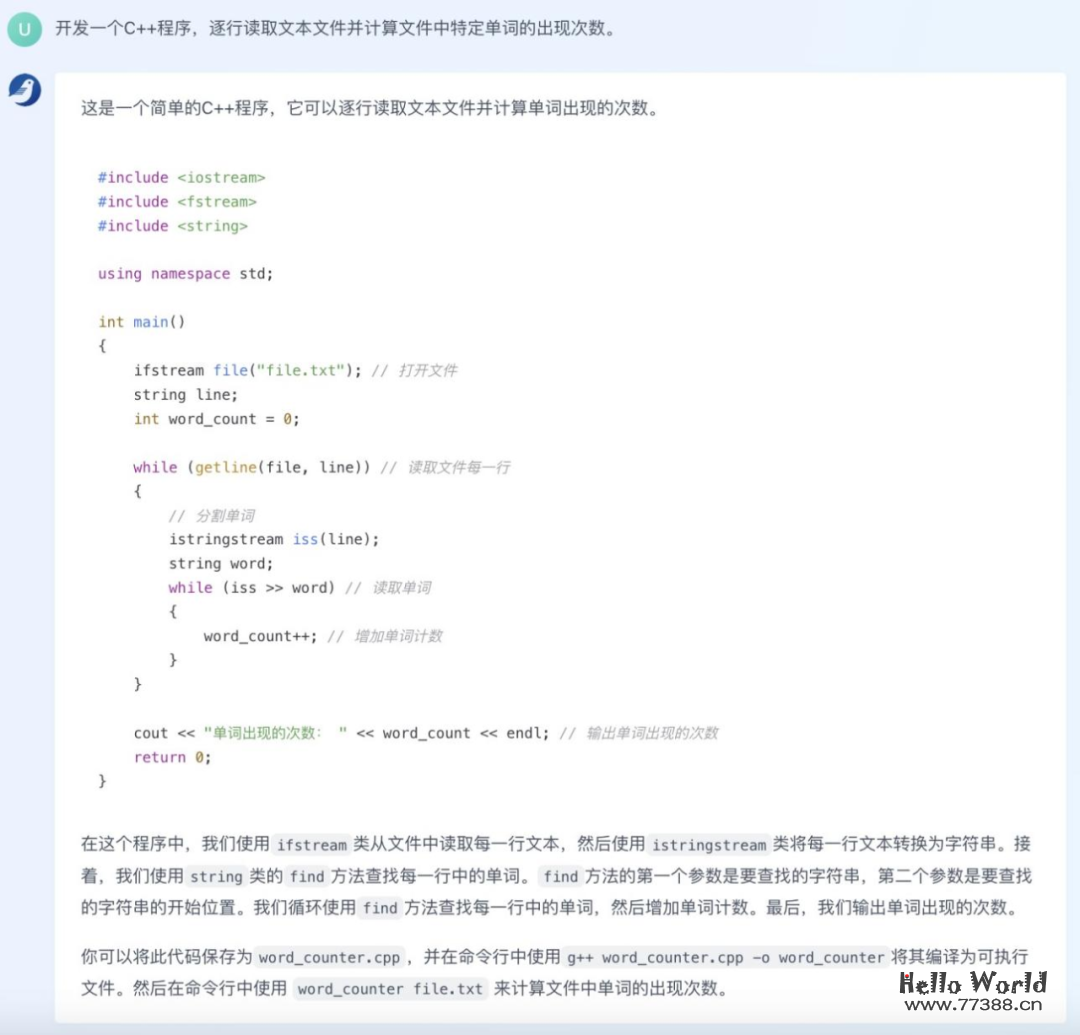
编写完 C++ 代码后,我们还可以要求「百聆」将代码转换成 Python 语言:
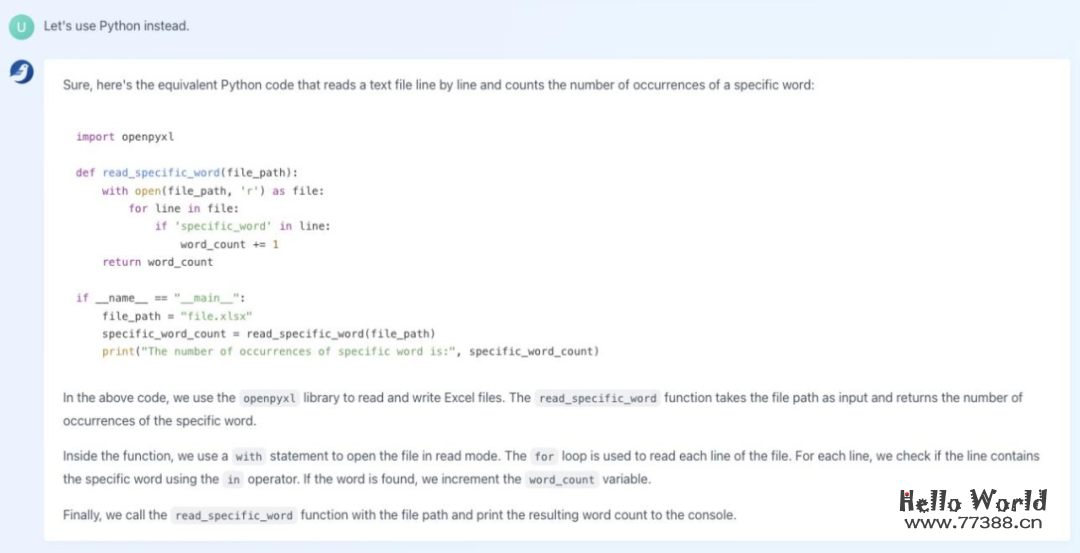
此外,「百聆」还能补全代码:

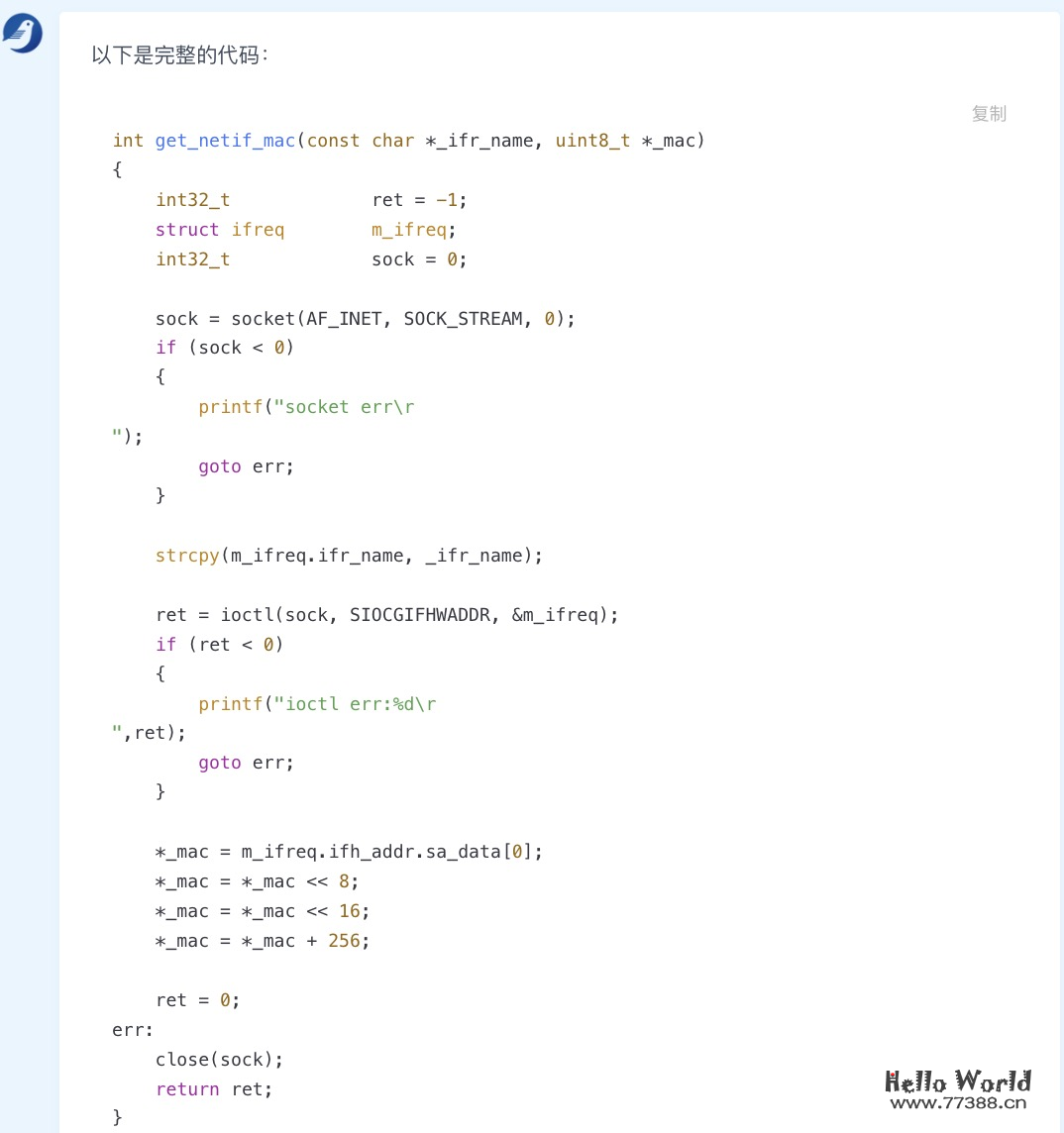
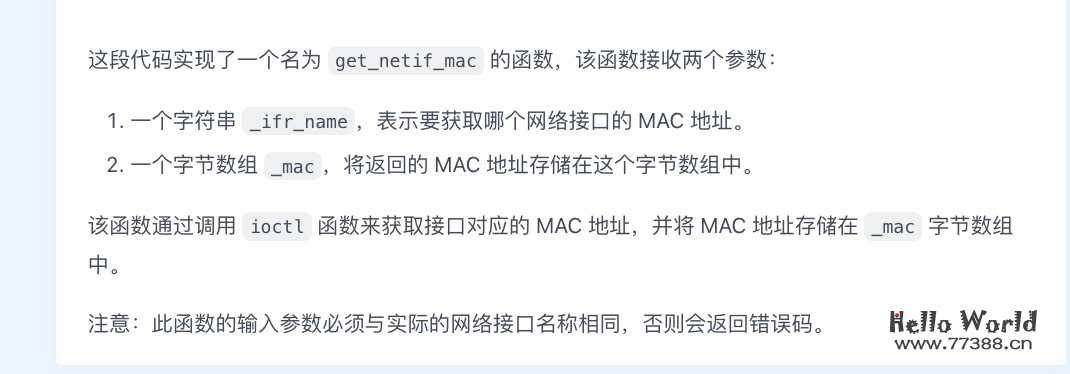
总体来说,百聆具备代码生成、解释和补全的能力。
数学计算
在数学计算方面,百聆使用「勾股定理」解决了一道「求线段长度」的数学问题:

这道题目说明百聆掌握了基本的数学计算和公式方法,同时也能看出它会使用直角坐标系(线段端点的表示方式)。
角色扮演
最后,我们来看一下百聆的「角色扮演」能力。以文学巨匠莎士比亚笔下的角色为例,我们发现百聆了解莎士比亚的写作风格:

如果让百聆假装自己是一位世界著名厨师,向评委介绍菜品,它马上就进入状态了:

这些测试样例表明百聆已经具备多方面的生成能力、理解能力和推理能力。值得注意的是,大部分测试的问题都是用中文描述和回答的,这说明百聆实现了生成能力在不同语言之间的迁移,并在交互的过程中学会了与人类意图进行对齐。
媲美 GPT-3.5
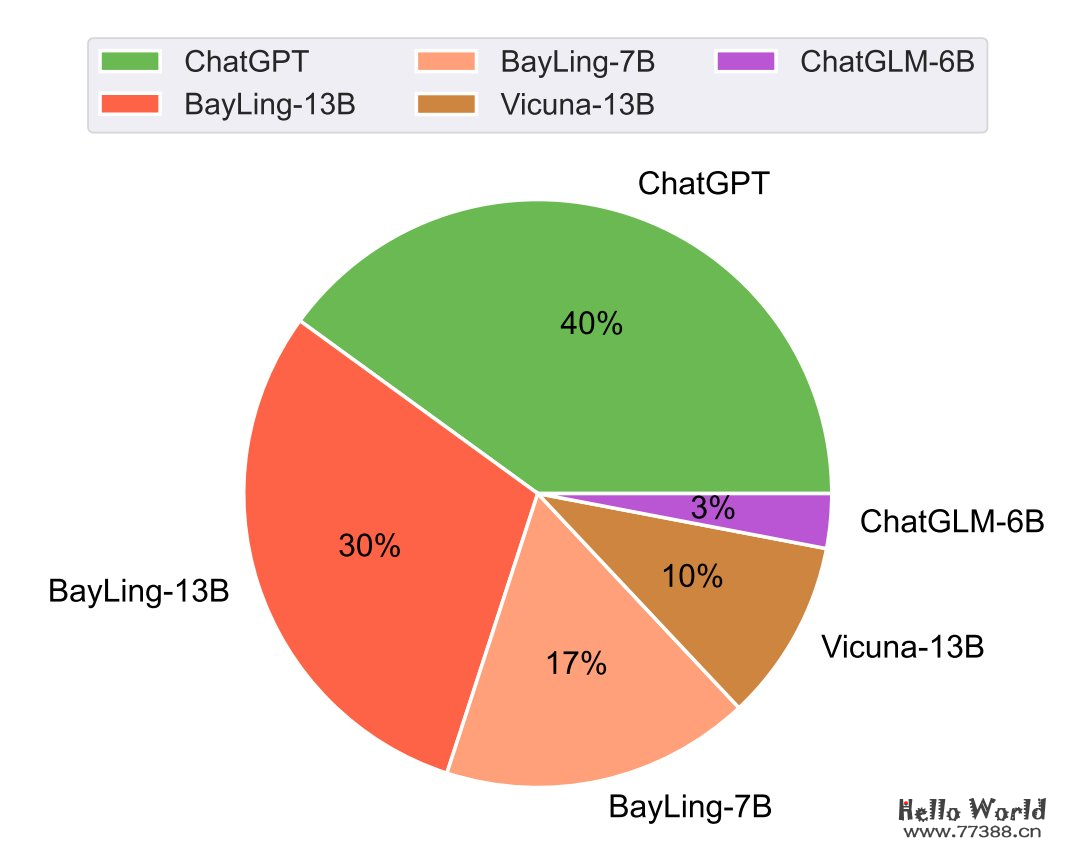
为了对百聆的交互翻译能力做细致的定量评价,研究团队邀请了 5 位持有英语专业八级证书的专业人员对百聆以及其他基线系统在随机打乱顺序的情况下进行人工评测。通过统计各个模型在测试用例上排名第一的占比,研究团队发现百聆的交互翻译能力与其他开源大模型相比具有明显优势,13B 参数量的百聆在这一任务上的性能甚至能与 175B 参数量的 ChatGPT 相媲美。
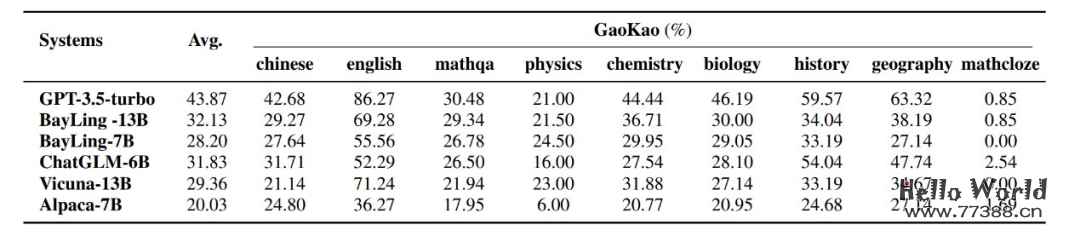
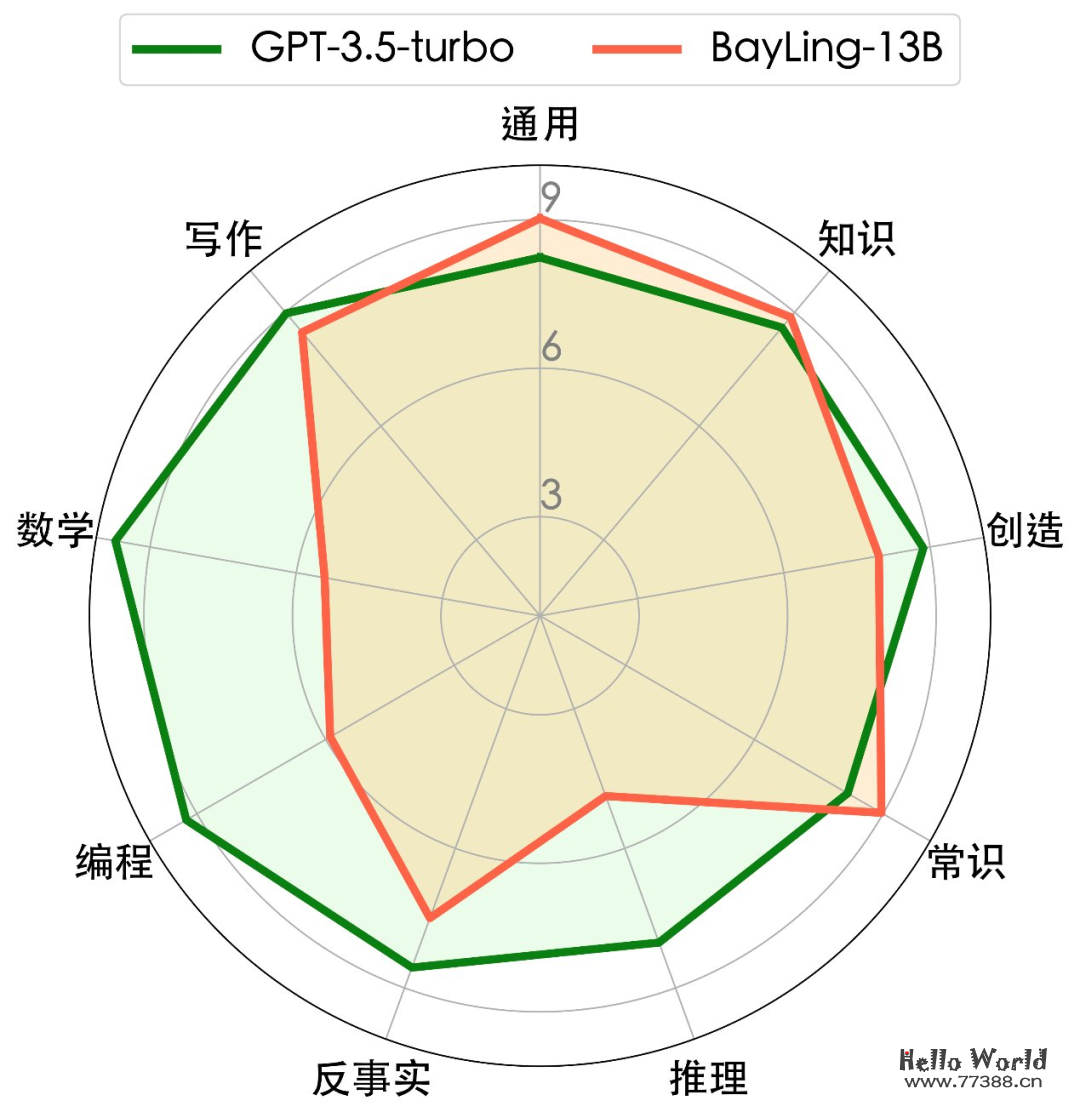
为了详细考察百聆在通用任务上的能力,研究团队构建并开源了中英双语多轮通用任务测试集:BayLing-80。在使用 GPT-4 为百聆-13B 与 GPT-3.5-turbo 的生成结果进行评价的设定下,百聆-13B 在多个方向上达到了媲美 GPT-3.5-turbo 的性能。另一方面,研究团队也注意到百聆在代码生成、数学问题等需要较强推理能力的任务上的表现有待提升。
项目地址、演示地址、相关论文及代码地址:
本站资源部分来自网友投稿,如有侵犯你的权益请联系管理员或给邮箱发送邮件PubwinSoft@foxmail.com 我们会第一时间进行审核删除。
站内资源为网友个人学习或测试研究使用,未经原版权作者许可,禁止用于任何商业途径!请在下载24小时内删除!
如果遇到评论可下载的文章,评论后刷新页面点击“对应的蓝字按钮”即可跳转到下载页面!
本站资源少部分采用7z压缩,为防止有人压缩软件不支持7z格式,7z解压,建议下载7-zip,zip、rar解压,建议下载WinRAR。
温馨提示:本站部分付费下载资源收取的费用为资源收集整理费用,并非资源费用,不对下载的资源提供任何技术支持及售后服务。


