



TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT
3 个月前,北大团队推出了 ChatExcel,让用户可以通过自然语言对话来操作 Excel 的各种功能,让人眼前一亮。但 ChatExcel 作为为了解决特定的问题而生的工具,其能力有限。
浙大团队近日推出的 TableGPT,是一款能完成对表格/数据库的各种分析、作图 、处理、建模等功能的刚性大模型。

论文地址:https://arxiv.org/pdf/2307.08674.pdf
摘要
自然语言处理在表格数据分析中的应用,包括将自然语言转化为SQL命令和将自然语言转化为VBA命令。然而,这些方法的性能表现并不理想,可能是因为编程代码的结构不够清晰,增加了自动后处理的复杂度。
本文介绍了TableGPT框架,将表格、自然语言和命令统一到一个GPT模型中,使数据解释和操作更加直观和用户友好。通过重新思考表格、自然语言和命令的交互,将几个核心组件集成到TableGPT中,推动了数据分析的发展。
通过重新思考表、自然语言和命令之间的交互,我们将几个核心组件集成到TableGPT中:全局表格表示、指挥链和领域感知微调。全局表格表示将整个表格编码为一个向量,提高了对表格数据的理解。指挥链将复杂任务分解为简单任务,提高了人机交互的效率和准确性。领域感知微调通过定制训练,使模型能够适应特定领域的表格和文本材料,提高了对特定领域数据的理解。我们开发了一个数据处理流水线,可以在只有少量数据的情况下取得显著的改进,从而减轻了训练LLMs和支持私有部署所需的资源消耗。
NL2SQL产生的非结构化代码给生产带来了挑战,因此我们主张使用结构化命令序列来简化后处理。我们认为,针对表格数据专门构建一个LLM是必要的,这强调了引入一个专门针对表格数据预训练的LLM的必要性。
TableGPT是一个先驱性的、统一的、完善的解决方案,通过自然语言驱动,实现了高效的表格数据处理、分析和可视化。TableGPT具有以下几个重要优点:
- TableGPT是一种语言驱动的EDA工具,能够理解用户意图并执行相应的操作,将处理结果以表格和文本形式返回给用户。
- 它采用统一的跨模态框架,能够全面理解用户查询、元知识和整个表格数据,从而更可靠地执行表格操作命令。
- 通过领域感知的微调,TableGPT能够处理不同领域的数据变异,并支持私密部署,保护数据隐私。
TableGPT与其前身不同的是,它采用了一种新的微调方法。微调是在包含2T个文本数据和0.3M个表格的广泛语料库上进行的,这个语料库提供了多样化的学习场景,包括用户查询命令序列对和公开可用的领域特定数据。

TableGPT的整体架构包括表格编码器和LLM。用户输入表格和查询后,TableGPT将其接收并提取表格的向量表示。这些表示与文本查询一起输入LLM进行推理。LLM识别用户的查询意图并生成包含命令序列和文本回复的输出。命令序列经过命令系统的纠错后,传递给执行器执行。最终输出包括经过操作的表格和文本回复,提供高效可靠的表格数据查询响应,简化数据分析。
表格的全局表示
大型语言模型(LLMs)与视觉和音频等多种模态相结合,例如OpenAI的CLIP和Wave2Vec和Tacotron等模型。这些模型通过共享潜在空间连接图像和文本,使用音频的频谱图来生成或理解语音。
目前,虽然语言模型的发展已经很先进,但是它们与表格数据的交互仍然受限。如何让语言模型理解和解释表格数据是一个重要问题。一些研究试图将表格数据的样本行直接转换为类似于句子的文本描述,而另一些研究则试图通过基于模板的列名、行业背景和其他元数据模式的提取来人工定义表格数据的全局表示。然而,这些方法只从表格数据中提取了部分信息,忽略了数据中固有的全局信息和行业背景。
表格数据是一种高度抽象的结构化数据类型,与图像、视频和音频不同,需要将整个表格嵌入到一个向量中。表格具有双重排列不变性结构,行或列的重新排序不会影响表格中包含的信息。此外,不同领域的表格大小和格式各异,使用统一的神经网络架构从多样的表格中提取特征具有挑战性。
本文介绍了一个级联表格编码器,可以从元数据和数字条目中提取知识,以实现全面的表格理解。然而,如何有效地从表格中提取全局表示仍然是一个开放性问题。
级联表格编码器。有经验的数据科学家在处理表格时,会先关注表头和特征列的分布,从而理解不同单元格的含义,而不是过于关注每个单元格的数字信息。他们采用的方法是级联表格编码。本文提出了一种新的级联表格编码器,将表格数据分为元数据和数值信息两部分,分别学习表格的结构和数字信息,帮助LLMs理解表格的全局信息。
使用改进的集合变换器作为表格编码器的主干,并增加了注意力机制,以捕捉表格数据中不同行或列之间的相互依赖关系,从而使模型能够理解表格数据的不同部分之间的关系。
这个编码器是使用掩码表格建模方法在一万个表格数据集上进行预训练的,类似于BERT中使用的掩码语言建模,但是适用于表格数据。学习到的表格表示不仅可以用于表格理解,还可以提高下游分类器的预测性能。
该方法在将表格、自然语言和命令整合到LLMs中方面迈出了重要一步。它提供了从表格中提取全局表示的全面方法,并使LLMs能够理解和操作。
链式命令
为了解决大型语言模型(LLMs)在数值推理方面的困难,我们提供了一系列预包装的函数命令,让LLMs调用。这些命令序列比text2SQL生成的SQL语句更容易检查和纠错。LLMs理解表格和用户输入的全局表示,生成一系列命令,由后端系统执行,从而修改表格。
用户查询通常模糊复杂,我们只能提供基本的表操作命令。教导LLM分解复杂模糊的查询至关重要。用户可能会使用原表中的同义词或翻译来查询指定的对象列,或者用户可能只有模糊的意图,无法清楚地表达需求。
Chain-of-thought方法强调将复杂推理分解为一系列中间步骤。Chain-of-command方法通过提供与这些中间步骤相关的逐步指令来增强Chain-of-thought。当用户查询过于模糊时,LLM可能会拒绝执行,并要求用户提供更具体的意图。
链式命令的目的是增强LLM在操作表格数据时的推理能力和鲁棒性。这种方法将用户输入转化为一系列中间命令操作,使LLMs能够更准确、更高效地符号化地操作表格。符号化指令的能力对于涉及历史数据的复杂和准确的实际应用特别有价值,例如管理环境中的记录和数据分析。
为了提高我们方法的性能和稳定性,我们构建了一个大量的命令链指令数据集,同时通过微调LLMs来适应命令,并采用上下文学习为命令链序列中的多个步骤提供提示。强大而准确的命令链过程使LLMs能够更好地推理表格数据并处理更复杂的情况。
链式命令方法有三个主要优点:提高了LLM的多跳推理能力,增强了处理复杂多表交互的能力,使LLM能够拒绝过于模糊的指令并要求更具体的意图。这种方法可以更好地处理边缘情况和意外情况,是实际应用的有前途的方法。
领域数据处理管道
大型语言模型虽然具有广泛的知识和对话能力,但由于缺乏专有领域数据的训练,其在处理特定行业的语言风格和逻辑方面表现不佳。为了解决这个问题,我们开发了一个高效的领域数据处理管道。
本流程旨在通过利用主动学习,从领域数据中精选出一组精心挑选的微调示例,以最小的计算开销和加速模型迭代的方式简化LLM的微调过程。这种资源的战略利用加快了模型的学习过程,从而加速了其迭代。
LLMs的文档检索能力得到了加强,利用向量数据库和LangChain等技术,从大量专有文档中检索相关信息,进一步丰富LLMs学习的上下文。
本流程是将LLMs快速且经济有效地适应各个特定行业数据需求的催化剂。它不仅解决了行业特定的语言风格和逻辑挑战,还使LLMs能够处理与表格交互的命令,整合自然语言、表格和命令的领域。
TableGPT是一个具有链式命令的文本生成模型,可以像人类专家一样思考命令的合理性,并在用户查询意图不明确时要求更详细的意图。
与以前使用命令的LLM的比较
TableGPT是一种将语言模型与表格结合的解决方案,与其他使用预定义外部命令的LLM不同,TableGPT通过针对表格相关任务进行微调,利用LLM架构的内在能力来处理表格任务。表1中详细比较了TableGPT与以前的命令使用LLM的区别。

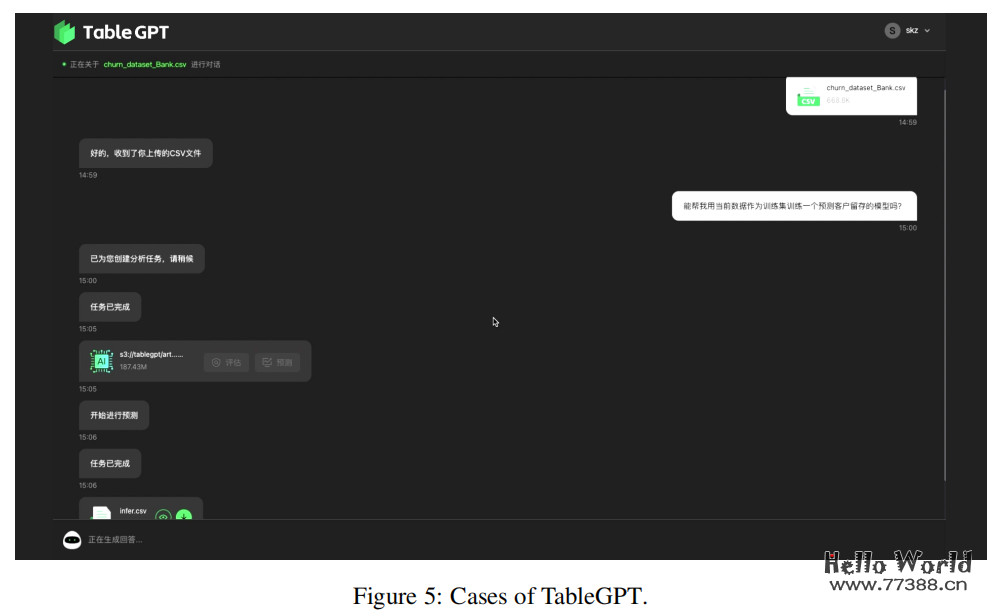
案例学习
本文介绍了一些案例,展示在图2-8中。未来还将发布更多案例。






总结
TableGPT是一个大型语言模型,用于表格分析,能够回答问题、操作数据、可视化信息、生成分析报告和进行预测。它解决了自然语言驱动的表格数据处理中的几个主要挑战,包括全面的表格理解、指令链生成和领域特定的微调。TableGPT有潜力重塑表格数据处理的格局,加速表格建模和探索性数据分析的效率,并赋能金融、交通、科学研究等各个领域。
本站资源部分来自网友投稿,如有侵犯你的权益请联系管理员或给邮箱发送邮件PubwinSoft@foxmail.com 我们会第一时间进行审核删除。
站内资源为网友个人学习或测试研究使用,未经原版权作者许可,禁止用于任何商业途径!请在下载24小时内删除!
如果遇到评论可下载的文章,评论后刷新页面点击“对应的蓝字按钮”即可跳转到下载页面!
本站资源少部分采用7z压缩,为防止有人压缩软件不支持7z格式,7z解压,建议下载7-zip,zip、rar解压,建议下载WinRAR。
温馨提示:本站部分付费下载资源收取的费用为资源收集整理费用,并非资源费用,不对下载的资源提供任何技术支持及售后服务。


