



在最近几个月中,以ChatGPT和GPT4为代表的AI应用和大型模型在全球范围内迅速走红,被认为是开启了新的科技工业革命和通用人工智能(AGI)的新起点。
不仅科技巨头们在争相推出新品,许多学术界和工业界的AI专家也纷纷加入了相关的创业浪潮。
生成式AI正在以惊人的速度迭代,持续狂飙!
然而,OpenAI并没有将其技术开源,这背后的技术细节是什么?如何快速跟进、追赶并参与到这一技术浪潮中?如何降低AI大型模型构建和应用的高昂成本?如何保护核心数据和知识产权,以免因使用第三方大型模型API而泄露?
作为目前最受欢迎的开源AI大型模型解决方案,知名开源项目Colossal-AI率先建立了包含监督数据集收集、监督微调、奖励模型训练和强化学习微调的完整RLHF流程。
这是目前最接近ChatGPT原始技术方案的实用开源项目!
开源地址:
该项目包含以下内容:
- 1. Demo:可直接在线体验模型效果,无需注册或等待列表;
- 2. 训练代码:开源完整的RLHF训练代码,已开源至包括7B和13B两种模型;
- 3. 数据集:开源104K中、英双语数据集;
- 4. 推理部署:4bit量化推理70亿参数模型仅需4GB显存;
- 5. 模型权重:仅需单台服务器少量算力即可快速复现;
- 6. 更大规模的模型、数据集和其他优化等将保持高速迭代添加。
平价模型,强大能力
即使只有不到百亿的参数,我们的模型也能够通过 RLHF 微调,掌握中英双语能力,达到与 ChatGPT 和 GPT-3.5 类似的效果。
我们的模型可以轻松应对常识问答、邮件写作、算法编写等任务。
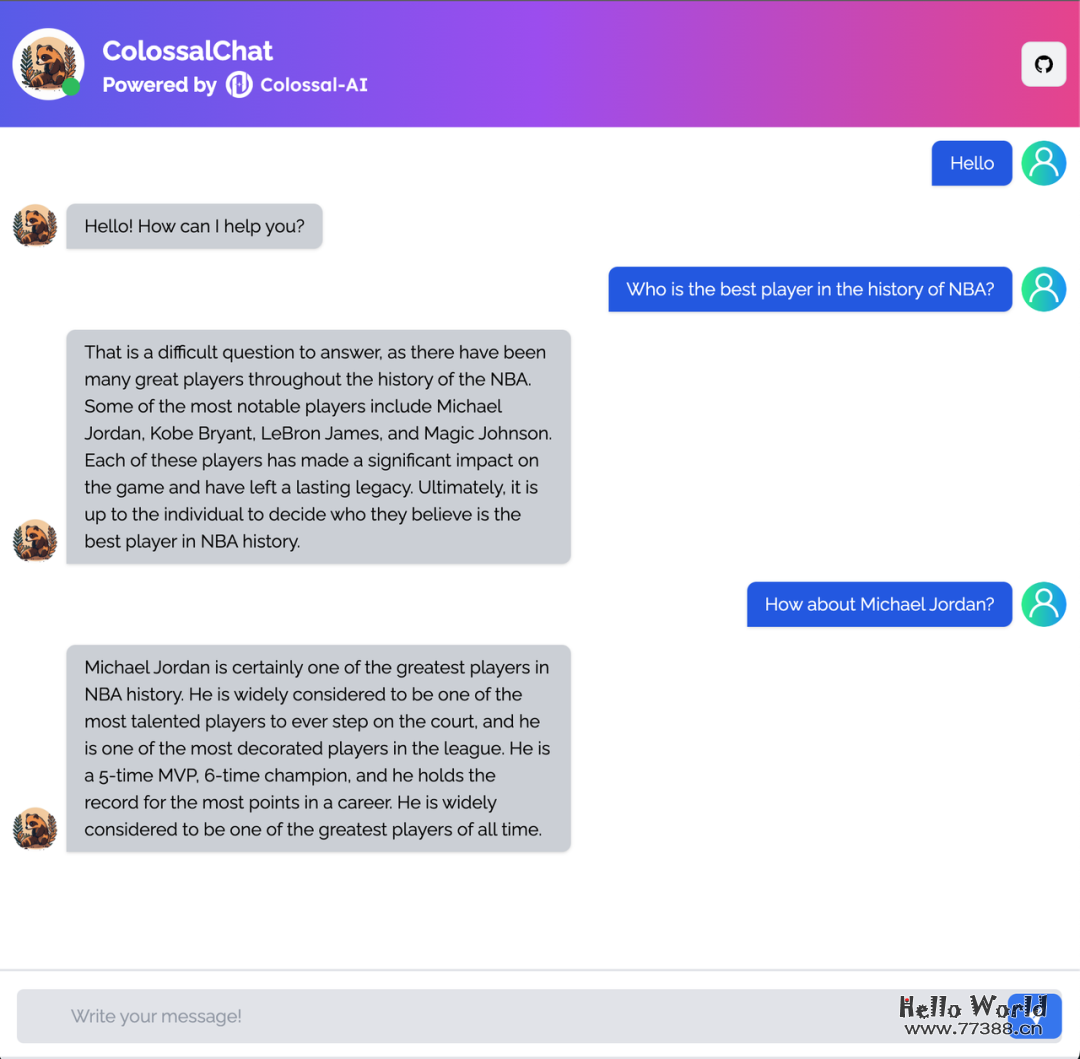
常识问答

中文应答

邮件写作
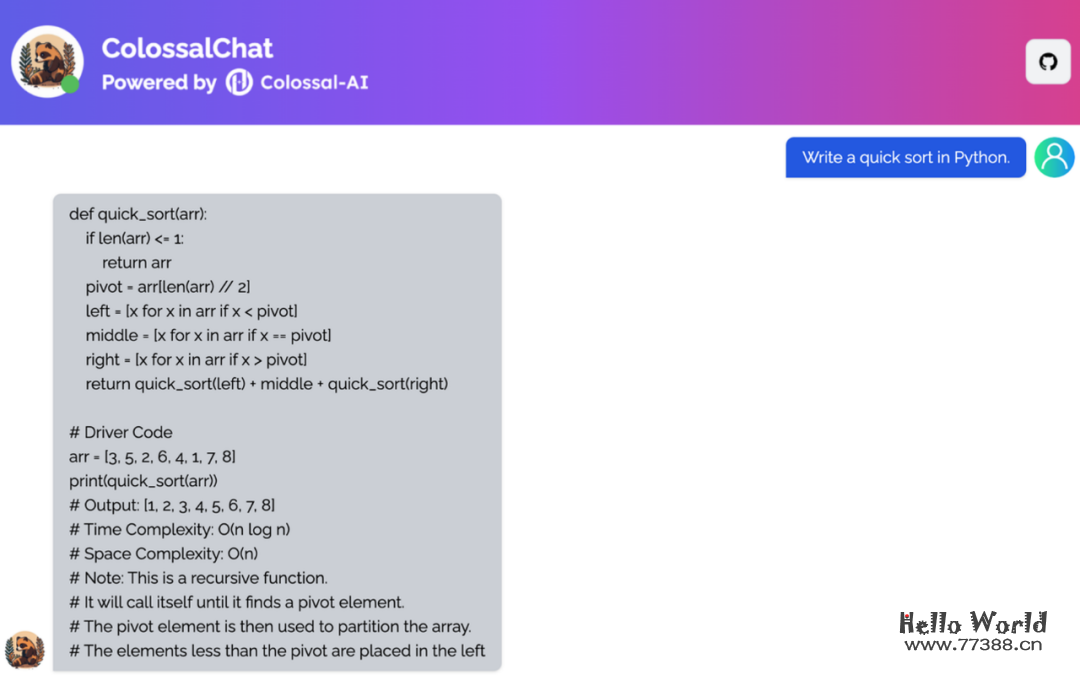
算法编写
完整 ChatGPT 克隆方案
虽然 ChatGPT 和 GPT-4 等 GPT 系列模型非常强大,但它们不太可能被完全开源。但是,开源社区一直在不断努力,例如 Meta 开源了 LLaMA 模型,该模型的参数量从 70 亿到 650 亿不等,仅使用 130 亿参数即可胜过 1750 亿的 GPT-3 模型在大多数基准测试的表现。然而,由于没有进行指令微调,该模型的实际生成效果不够理想。
斯坦福的 Alpaca 通过调用 OpenAI API,以 self-instruct 方式生成训练数据,使得仅有 70 亿参数的轻量级模型以极低成本微调后,即可获得媲美 GPT-3.5 这样千亿参数的超大规模语言模型的对话效果。然而,现有的开源方案都只得到了人类反馈强化学习(RLHF)中第一步的监督微调模型,没有进行后续的对齐和微调工作。同时,Alpaca 的训练数据集过小,语料只有英文,也在一定程度上限制了模型的性能。
ChatGPT 和 GPT-4 的惊艳效果在于将 RLHF 引入训练过程,使得生成内容更加符合人类价值观。我们的模型也采用了这种方法,以确保生成的内容符合人类价值观。

ColossalChat是基于LLaMA模型的开源项目,它是Colossal-AI推出的第一个包含完整RLHF流程的类Chat模型复现方案。该项目是目前最接近ChatGPT原始技术路线的实用开源项目,为用户提供了高效、可靠的聊天体验。
训练数据集开源
ColossalChat公开了一个包含约10万条中英双语问答的开源数据集。
该数据集是通过收集和清洗社交平台上真实的提问场景作为种子数据集,并利用self-instruct技术扩充数据而生成的。
这个数据集花费了约900美元进行标注,相比其他self-instruct方法生成的数据集,该数据集的种子数据更加真实、丰富,生成的数据集涵盖的话题更多。
这个数据集可以同时用于微调和RLHF训练,通过高质量的数据,ColossalChat能够进行更好的对话交互,同时支持中文。

RLHF算法详解
RLHF-Stage1 是基于有监督的微调方式,使用前文提到的数据集对模型进行训练。
RLHF-Stage2 训练了奖励模型,通过人工排序预测同一个提示的不同输出,以获得相应的分数,并对奖励模型进行监督学习。
RLHF-Stage3 采用强化学习算法,是整个训练流程中最复杂的部分:

ColossalChat的PPO部分分为两个阶段:Make Experience和参数更新。在Make Experience阶段,使用SFT、Actor、RM和Critic模型计算生成Experience并存入buffer中。在参数更新阶段,利用Experience计算策略损失和价值损失。
在PTX部分,ColossalChat计算Actor输出response和输入语料的回答部分的交叉熵损失函数,以保持语言模型原有性能防止遗忘,并在PPO梯度中加入预训练梯度。最后,将策略损失、价值损失和PTX损失加和进行反向传播和参数更新。
如果您想快速上手,ColossalChat已经开源了基于LLaMA模型的完整代码;
可以复现训练ChatGPT三个阶段。
第一阶段是训练SFT模型:
# Training with a 4-GPU servers
colossalai run --nproc_per_node=4 train_sft.py \
--pretrain "/path/to/LLaMa-7B/" \
--model 'llama' \
--strategy colossalai_zero2 \
--log_interval 10 \
--save_path /path/to/Coati-7B \
--dataset /path/to/data.json \
--batch_size 4 \
--accimulation_steps 8 \
--lr 2e-5
第二阶段是训练奖励模型:
# Training with a 4-GPU servers
colossalai run --nproc_per_node=4 train_reward_model.py \
--pretrain "/path/to/LLaMa-7B/" \
--model 'llama' \
--strategy colossalai_zero2 \
--dataset /path/to/datasets
第三阶段是使用RL训练:
# Training with a 8-GPU servers
colossalai run --nproc_per_node=8 train_prompts.py prompts.csv \
--strategy colossalai_zero2 \
--pretrain "/path/to/Coati-7B" \
--model 'llama' \
--pretrain_dataset /path/to/dataset
在获得最终模型权重后,您还可以通过量化降低推理硬件成本,并启动在线推理服务。只需要单张约4GB显存的GPU,即可完成70亿参数模型推理服务部署。
python server.py /path/to/pretrained --quant 4bit --gptq_checkpoint /path/to/coati-7b-4bit-128g.pt --gptq_group_size 128
系统性能优化与开发加速
ColossalChat 能够快速跟进 ChatGPT 完整 RLHF 流程复现,离不开 AI 大模型基础设施 Colossal-AI 及相关优化技术的底座支持。相比 Alpaca 采用的 FSDP(Fully Sharded Data Parallel),Colossal-AI 可以提升两倍以上的训练速度,为开发者提供了更高效的训练和推理体验。
作为 AI 大模型开发系统的基础设施
Colossal-AI 为该方案提供了强有力的支持。它基于 PyTorch 高效快速部署 AI 大模型训练和推理,从而降低了 AI 大模型应用的成本。Colossal-AI 的开发团队由加州伯克利大学杰出教授 James Demmel 和新加坡国立大学校长青年教授尤洋领导,他们的专业知识和经验保证了 Colossal-AI 的高质量和可靠性。
自开源以来,Colossal-AI 已经多次在 GitHub 热榜位列世界第一,获得了约两万颗 GitHub Star,并成功入选了 SC、AAAI、PPoPP、CVPR、ISC 等国际 AI 与 HPC 顶级会议的官方教程。这些成就证明了 Colossal-AI 在 AI 大模型开发领域的领先地位,为开发者提供了更好的开发体验和更高效的解决方案。
使用 ZeRO + Gemini 减少内存冗余
Colossal-AI 提供了 ZeRO + Gemini 技术,可以有效减少内存冗余,提高内存使用效率,降低成本。ZeRO 技术可以优化内存使用,使得更大的模型可以在低成本的硬件上运行,同时不影响计算粒度和通信效率。自动 Chunk 机制可以进一步提升 ZeRO 的性能,减少通信次数并避免内存碎片。Gemini 技术可以将优化器状态从 GPU 显存卸载到 CPU 内存或硬盘空间,以突破 GPU 显存容量限制,扩展可训练模型的规模,降低 AI 大模型应用成本。
使用 LoRA 低成本微调
Colossal-AI 还支持使用 LoRA 低秩矩阵微调方法,对 AI 大模型进行低成本微调。LoRA 方法认为大语言模型是过参数化的,而在微调时,只有低秩矩阵参数需要被调整。因此,可以将这个矩阵分解为两个更小的矩阵的乘积。在微调过程中,大模型的参数被固定,只有低秩矩阵参数被调整,从而显著减小了训练所需的参数量,并降低成本。这种低成本微调方法可以帮助用户更加高效地训练大型模型,提高训练效率和性能。
低成本量化推理

为了降低推理部署的成本,Colossal-AI采用了GPTQ 4bit量化推理技术。相比传统的RTN(rount-to-nearest)量化技术,它在GPT/OPT/BLOOM类模型上表现更好,能够获得更好的Perplexity效果。
与常见的FP16推理相比,GPTQ 4bit量化推理技术可以将显存消耗降低75%,同时只损失了极少量的吞吐速度和Perplexity性能。
以ColossalChat-7B为例,使用4bit量化推理技术时,70亿参数模型仅需大约4GB显存即可完成短序列(生成长度为128)推理,甚至可以在普通消费级显卡上完成(例如RTX 3060 Laptop),只需要一行代码即可使用。
if args.quant == '4bit':
model = load_quant(args.pretrained, args.gptq_checkpoint, 4, args.gptq_group_size)
如果采用高效的异步卸载技术(offload),还可以进一步降低显存要求,使用更低成本的硬件推理更大的模型。
开放协作
尽管已经进一步引入RLHF,但由于算力和数据集有限,在部分场景下的实际性能仍有提升空间。

幸运的是,不同以往 AI 大模型与前沿技术仅由少数科技巨头垄断,PyTorch、Hugging Face 和 OpenAI 等开源社区与初创企业在本轮浪潮中也起到了关键作用。
借鉴开源社区的成功经验,Colossal-AI 欢迎各方参与共建,拥抱大模型时代!
可通过以下方式联系或参与:
- 在 GitHub 发布 issue 或提交 pull request (PR)
- 加入 Colossal-AI 用户微信或 Slack 群交流
- 发送正式合作提案到邮箱 youy@comp.nus.edu.sg
本站资源部分来自网友投稿,如有侵犯你的权益请联系管理员或给邮箱发送邮件PubwinSoft@foxmail.com 我们会第一时间进行审核删除。
站内资源为网友个人学习或测试研究使用,未经原版权作者许可,禁止用于任何商业途径!请在下载24小时内删除!
如果遇到评论可下载的文章,评论后刷新页面点击“对应的蓝字按钮”即可跳转到下载页面!
本站资源少部分采用7z压缩,为防止有人压缩软件不支持7z格式,7z解压,建议下载7-zip,zip、rar解压,建议下载WinRAR。
温馨提示:本站部分付费下载资源收取的费用为资源收集整理费用,并非资源费用,不对下载的资源提供任何技术支持及售后服务。


